트러블슈팅 : 디스크 사용량으로 인한 색인 불가 문제
운영 중인 Elasticsearch 클러스터에서 갑자기 문서가 색인되지 않고, 클라이언트 측에서 403 Forbidden Error가 발생하는 상황을 겪을 수 있습니다. 이는 단순한 권한 문제처럼 보이지만, 실제로는 클러스터의 디스크 사용량과 밀접하게 관련이 있습니다.
1. 문제 원인: 디스크 사용량 보호 장치
Elasticsearch는 노드의 디스크 사용량이 일정 수준을 초과하면 클러스터 안정성을 위해 색인을 제한하는 보호 장치를 내장하고 있습니다. 디스크가 가득 차면 운영 체제 자체도 정상적으로 동작하지 않을 수 있기 때문입니다.

이 동작은 다음 설정값들로 제어됩니다.
- cluster.routing.allocation.disk.threshold_enabled
디스크 사용량 보호 장치 활성화 여부 (기본적으로 활성화됨) - cluster.routing.allocation.disk.watermark.low (기본값: 85%)
이 값 이상일 경우, 신규 샤드 배치를 중단합니다. - cluster.routing.allocation.disk.watermark.high (기본값: 90%)
이 값 이상일 경우, 기존 샤드를 다른 노드로 이동시키기 시작합니다. - cluster.routing.allocation.disk.watermark.flood_stage (기본값: 95%)
이 값 이상일 경우, 인덱스가 Read-Only 상태로 전환되며 색인이 차단됩니다. 검색만 가능해집니다.
2. 해결 방법
문제가 발생했을 때는 다음 단계로 대응할 수 있습니다.
- 디스크 공간 확보
- 데이터 노드를 증설하거나
- 불필요한 인덱스를 삭제하여 여유 공간을 마련합니다.
- 인덱스 Read-Only 상태 해제
디스크 공간을 확보한 뒤에도 인덱스는 여전히 read_only_allow_delete 상태일 수 있습니다. 이 경우 명시적으로 설정을 풀어주어야 색인이 다시 가능합니다. 그렇지 않으면 403 Forbidden Error가 계속 발생할 수 있습니다.
정리
- Elasticsearch는 디스크 과부하로 인한 장애를 방지하기 위해 자동 보호 장치를 제공합니다.
- flood_stage(95%)를 초과하면 색인이 차단되고, 검색만 가능한 상태가 됩니다.
- 해결을 위해서는 디스크 공간 확보 → 인덱스 Read-Only 해제의 순서가 필요합니다.
트러블슈팅 : 색인 누락과 Rejected 에러 대응
운영 중인 Elasticsearch 클러스터에서 간헐적인 색인 누락과 Rejected 에러가 발생하는 경우가 종종 있습니다.
1. 문제 원인
운영 중인 클러스터에서 다음과 같은 두 가지 문제가 관찰되었습니다.
- 색인 과정에서 일부 문서가 간헐적으로 누락됨
- 노드에서 Rejected 에러가 발생함
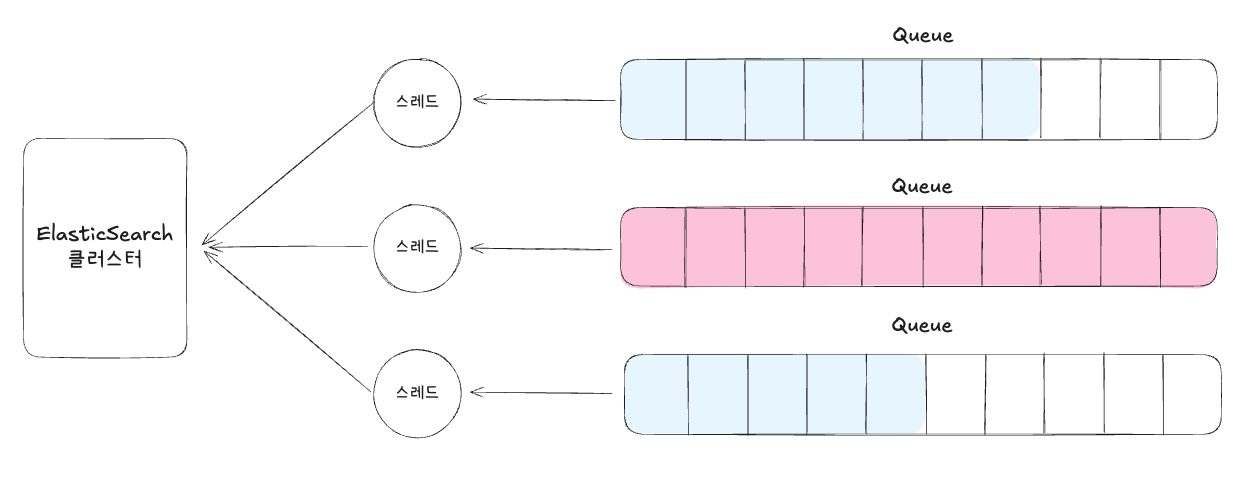
이러한 문제는 특히 대량의 색인 요청이 순간적으로 몰릴 때 자주 발생합니다. Elasticsearch는 색인 및 검색 요청을 처리하기 위해 스레드 풀(thread pool) 구조를 사용합니다. 각 스레드는 요청을 처리하며, 만약 모든 스레드가 바쁘다면 요청은 큐(queue) 에 쌓이게 됩니다.
하지만 문제는 이 큐마저 모두 가득 찼을 때 발생합니다. 큐가 초과되면 새롭게 들어온 요청은 더 이상 처리할 수 없으므로 Rejected 에러가 반환되고, 이 과정에서 색인 누락 문제가 나타납니다.
2. 해결 방법
이 문제를 해결하기 위해 고려할 수 있는 방법은 크게 두 가지입니다.
1. 데이터 노드 증설
클러스터의 처리량 부족이 근본 원인이라면, 가장 확실한 해결 방법은 데이터 노드를 증설하는 것입니다. 노드를 늘리면 색인 요청을 처리할 수 있는 리소스가 증가하므로 Rejected 에러 발생 가능성을 크게 줄일 수 있습니다.
2. 큐 사이즈 증설
만약 클러스터의 기본 처리량은 충분하지만 특정 시간대에만 요청이 폭증하는 경우라면 큐 사이즈를 늘려 일시적으로 대응할 수 있습니다.
thread_pool.bulk.queue_size: 1000
이를 통해 순간적으로 몰리는 요청을 버퍼링할 수 있으며, 안정적인 색인 처리가 가능해집니다. 다만, 이는 임시적인 대응일 뿐, 근본적으로는 처리량 확충(노드 증설) 이 더 권장됩니다.
정리
Elasticsearch에서 발생하는 간헐적인 색인 누락과 Rejected 에러는 스레드 풀 및 큐 포화가 주요 원인입니다.
- 평상시에도 처리량이 부족하다면 데이터 노드 증설이 필요합니다.
- 순간적인 요청 폭주라면 큐 사이즈 증설이 효과적입니다.
'ElasticSearch' 카테고리의 다른 글
| ElasticSearch에 대해 알아보자 - (4) 트러블슈팅 : 클러스터의 상태 이상, 샤드 배치 이상 (0) | 2025.09.10 |
|---|---|
| ElasticSearch에 대해 알아보자 - (3) 검색 과정 이해하기 (0) | 2025.09.10 |
| ElasticSearch에 대해 알아보자 - (2) 색인 과정 이해하기 (0) | 2025.09.09 |
| ElasticSearch에 대해 알아보자 - (1) 용어 이해하기 (클러스터, 노드, 인덱스, 샤드, 매핑) (0) | 2025.09.05 |



