검색 (Search)

이전에 색인 과정을 살펴 보면, inverted index를 생성하게 됩니다. inverted index는 검색 과정에서 매우 중요한 부분 입니다.

검색 과정을 살펴보면 검색어 분석을 통해 inverted index를 검색하게 됩니다.
역색인 (Inverted Index)
Inverted Index(역색인)는 검색 엔진의 핵심 데이터 구조로, 문자열을 분석한 결과를 저장하고 있는 구조체 입닌다. inverted index를 활용해 특정 단어가 어떤 문서에 포함되어 있는지를 빠르게 찾을 수 있게 해줍니다.
- 일반적인 색인(Forward Index): 문서 → 단어 목록
- 역색인(Inverted Index): 단어 → 문서 목록
즉, "어떤 문서에 이 단어가 있나?" 를 빠르게 찾을 수 있도록 설계된 자료구조입니다.
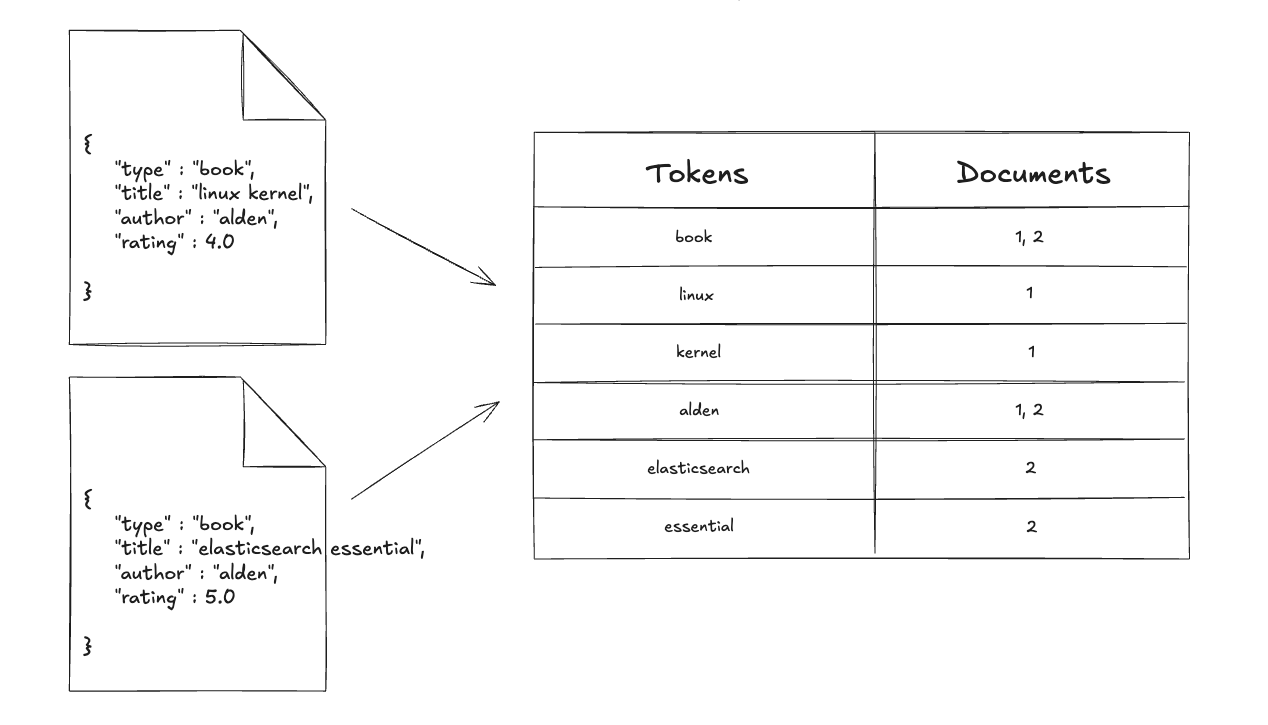
문서가 저장되면 단순히 원문 그대로 보관하는 것이 아니라, 텍스트를 토큰화(Tokenization) 과정을 거쳐 단어 단위로 분리합니다. 그 후 각 단어가 어떤 문서에 등장했는지를 매핑하여 색인을 구성합니다.
예를 들어, 첫 번째 문서에는 "linux kernel", 두 번째 문서에는 "elasticsearch essential"이라는 제목이 들어 있습니다. 이 텍스트들은 분석기를 거쳐 각각 linux, kernel, elasticsearch, essential 같은 토큰으로 나뉘게 됩니다. 그런 다음 Inverted Index는 각 단어를 Key로 하여, 해당 단어가 포함된 문서 ID를 Value로 저장합니다.
그 결과, "linux"라는 단어로 검색하면 문서 1을, "elasticsearch"라는 단어로 검색하면 문서 2를, "book"이나 "alden" 같은 단어로 검색하면 문서 1과 2 모두를 빠르게 찾을 수 있습니다.
즉, Inverted Index는 단어 → 문서 구조를 가지기 때문에, 사용자가 특정 키워드를 입력했을 때 해당 단어가 포함된 문서를 효율적으로 찾아낼 수 있는 것입니다.
애널라이저 (Analyzer)
애널라이저는 엘라스틱서치에서 텍스트를 검색 가능한 형태로 변환하기 위해 사용하는 도구입니다. 즉, 원본 문장을 그대로 저장하는 것이 아니라, 검색 효율을 높일 수 있도록 단어를 잘게 쪼개고 가공하는 과정을 거치는데, 이 전 과정을 담당하는 것이 애널라이저입니다.

애널라이저의 구성 요소
애널라이저는 크게 세 가지 단계로 동작합니다.
- Character Filter
- 텍스트가 토큰화되기 전에 전처리를 수행합니다.
- 예: HTML 태그 제거, 특수문자 변환, 특정 문자열 치환 등
- Tokenizer
- 문장을 단어 단위로 분리하는 역할을 합니다.
- 예: "Elasticsearch is powerful" → ["Elasticsearch", "is", "powerful"]
- 기본적으로 standard tokenizer를 많이 사용하지만, whitespace tokenizer, keyword tokenizer 등 다양한 방식을 지원합니다.
- Token Filter
- 토크나이저로 잘라낸 단어를 추가 가공합니다.
- 예: 소문자 변환, 불용어(stop words) 제거, 어간 추출(stemming), 동의어 처리(synonym) 등
검색 과정과 Analyzer, Inverted Index의 역할

엘라스틱서치에서 검색이 동작하는 과정은 단순히 “문자열 비교”가 아닙니다. 사용자가 입력한 검색어는 Analyzer(애널라이저)를 거쳐 토큰(Token)으로 변환되고, 이 토큰을 기반으로 Inverted Index(역색인)에서 문서를 찾아내는 방식으로 동작합니다.
- 검색어 분석
- 사용자가 “엘라스틱 서치”라는 검색어를 입력하면, 먼저 애널라이저가 적용됩니다.
- 애널라이저는 검색어를 토큰으로 변환하는데, 여기서는 "엘라스틱", "서치" 두 개의 토큰이 만들어집니다.
- Inverted Index 검색
- 생성된 토큰을 가지고 역색인을 탐색합니다.
- 예를 들어 "엘라스틱"이라는 토큰이 포함된 문서 목록, "서치"라는 토큰이 포함된 문서 목록을 각각 찾습니다.
- 이후 검색 엔진은 두 결과를 조합하여 최종적으로 매칭되는 문서들을 반환합니다.
- 검색 결과 표시
- 역색인에서 찾아낸 문서들이 사용자의 검색 결과로 화면에 노출됩니다.
검색어 입력 → Analyzer로 토큰 변환 → Inverted Index에서 매칭 → 결과 반환 의 흐름으로 검색이 진행됩니다. 이 과정 덕분에 엘라스틱서치는 방대한 데이터 속에서도 빠르고 정확한 검색을 제공할 수 있습니다.
검색 성능
검색 요청은 Primary 샤드와 Replicas 샤드 모두가 처리 할 수 있습니다. (색인 요청은 Primary 샤드만 가능합니다.)
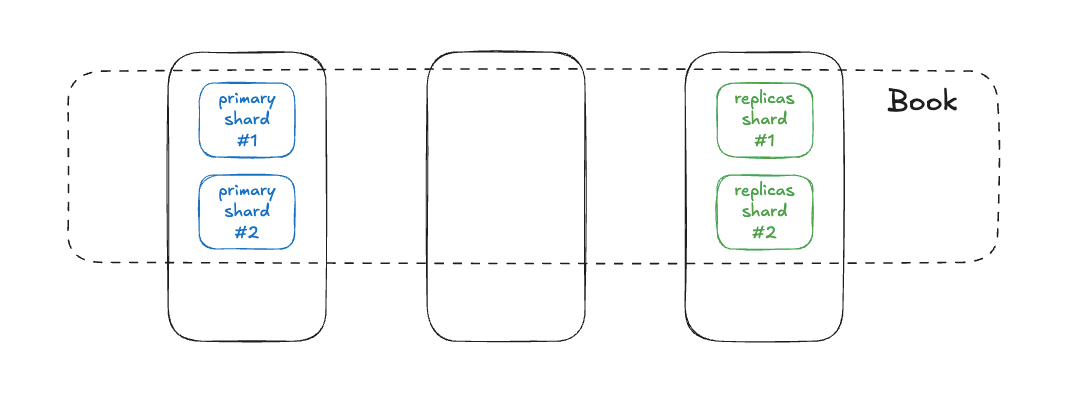
검색 성능에 문제가 있다면 클러스터 로서의 이점을 잘 살리고 있는지 먼저 살펴 봐야 합니다. 엘라스틱서치에서 검색 요청은 Primary 샤드뿐만 아니라 Replica 샤드에서도 처리할 수 있습니다. 색인(Indexing) 요청은 반드시 Primary 샤드에서만 가능하지만, 검색은 Primary와 Replica가 동일한 데이터를 가지고 있기 때문에 어느 쪽에서든 처리할 수 있습니다.
데이터의 트래픽이 노드 3번으로 몰려든다면 Primary 샤드 혹은 Replicas 샤드를 통해서 처리가 가능합니다. 하지만 노드 2번은 샤드가 없기 때문에 클러스터의 이점을 올바르게 활용하지 못 합니다.
이런 경우 성능을 개선하고 싶을 때, 색인 성능이 충분하다면 Primary 샤드를 굳이 늘릴 필요는 없습니다. 하지만 검색 성능을 늘리고 싶다면 Replicas 샤드를 늘려 성능을 높일 수 있습니다.

검색 성능을 향상시키려면 Replica 샤드를 적극적으로 활용하는 것이 좋습니다.
- Replica 샤드를 늘리면 검색 요청을 더 많은 노드로 분산할 수 있습니다.
- 노드가 부족하다면 새 노드를 추가하고 Replica 샤드를 배치할 수도 있습니다.
- 이렇게 하면 트래픽이 특정 노드에 집중되지 않고, 전체 클러스터가 고르게 검색 요청을 처리할 수 있습니다.
반대로 Primary 샤드는 임의로 늘릴 수 없습니다. Primary 샤드 개수는 인덱스를 생성할 때 고정되며, 나중에 바꾸려면 새 인덱스를 만들고 데이터를 재색인해야 합니다. Primary 샤드를 늘리면 문서 라우팅 규칙 자체가 달라지기 때문에 단순히 추가하는 방식으로는 불가능합니다.
- 색인 성능 개선이 필요하다면 Primary 샤드의 수와 크기를 재설계해야 합니다.
- 검색 성능 개선이 필요하다면 Replica 샤드를 늘려 분산 검색을 활용하는 것이 효과적입니다.
- 즉, Primary는 데이터 분산 단위를 정의하는 역할을 하고, Replica는 검색 성능과 가용성을 높이는 역할을 합니다.
Text와 Keyword
둘 다 문자열을 나타내기 위한 타입 입니다. 엘라스틱서치에서 문자열을 저장할 때는 주로 text 타입과 keyword 타입을 사용합니다. 두 타입은 비슷해 보이지만, 동작 방식과 목적이 완전히 다릅니다.
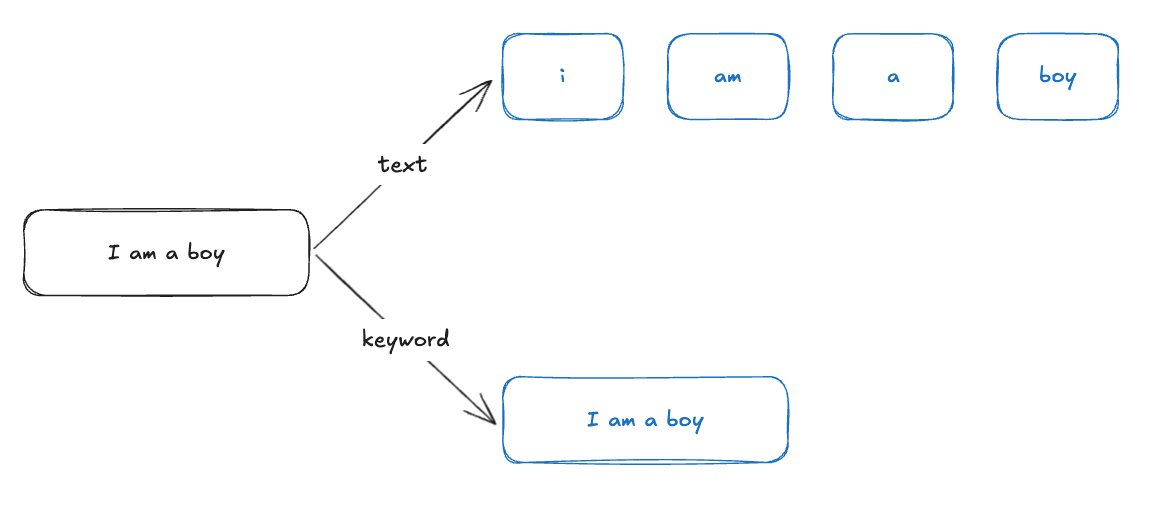
1. text 타입
- 용도: 전문 검색(Full-text search)
- 저장 방식:
- Analyzer(애널라이저)를 거쳐 텍스트가 토큰 단위로 분리됨
- 예: "Elasticsearch is powerful" → ["elasticsearch", "powerful"]
- 검색 방식:
- match 쿼리 등으로 텍스트 검색 가능
- 형태소 분석, 불용어 제거, 소문자 변환 등 다양한 텍스트 분석 적용 가능
- 특징:
- 검색 정확도를 높이기 위해 텍스트를 **분석(Analyzed)**하여 저장
- 정렬(sort)이나 집계(aggregation)에는 바로 사용하기 어려움
2. keyword 타입
- 용도: 정확한 값 검색 및 정렬/집계 (Exact Matching)
- 저장 방식:
- 텍스트 전체를 그대로 저장 (Analyzed되지 않음)
- 예: "Elasticsearch is powerful" → ["Elasticsearch is powerful"]
- 검색 방식:
- term 쿼리로 정확히 일치하는 값 검색
- 정렬(sort), 집계(aggregation), 필터링 등에 사용
- 특징:
- 분석 과정 없이 원본 문자열을 기준으로 매칭
- 예: 이메일 주소, ID, 상태값(status), 태그 등
따라서 일반적으로 Keyword 타입이 색인 속도가 더 빠릅니다. CPU를 사용하는 작업을 하지 않기 때문입니다. 여기서 중요한 점은 문자열 필드는 동적 매핑이 되었을 때 text와 keyword 타입 두 개가 모두 생성 됩니다. 따라서 문자열의 특성에 따라 text와 keyword를 정적 매핑 해 주면 성능에도 도움이 됩니다.

당연한 소리지만 하나의 문장에 구성된 단어로 검색이 필요한 경우는 Text 방식이 좋을 수 있으며, 정확히 문장과 일치해야 하는 검색이 필요한 경우는 keyword 방식이 좋을 수 있습니다.
'ElasticSearch' 카테고리의 다른 글
| ElasticSearch에 대해 알아보자 - (5) 트러블슈팅 : 문서 색인 불가 (1) | 2025.09.11 |
|---|---|
| ElasticSearch에 대해 알아보자 - (4) 트러블슈팅 : 클러스터의 상태 이상, 샤드 배치 이상 (0) | 2025.09.10 |
| ElasticSearch에 대해 알아보자 - (2) 색인 과정 이해하기 (0) | 2025.09.09 |
| ElasticSearch에 대해 알아보자 - (1) 용어 이해하기 (클러스터, 노드, 인덱스, 샤드, 매핑) (0) | 2025.09.05 |



