ElasticSearch Indexing
색인 이란?
Elasticsearch에서 색인(Indexing)은 데이터를 문서(Document) 단위로 인덱스에 저장하고, 검색할 수 있도록 구조화하는 과정을 의미합니다. 단순히 저장만 하는 것이 아니라, 검색 성능을 높이기 위해 역색인(Inverted Index) 구조를 생성하는 게 핵심입니다.
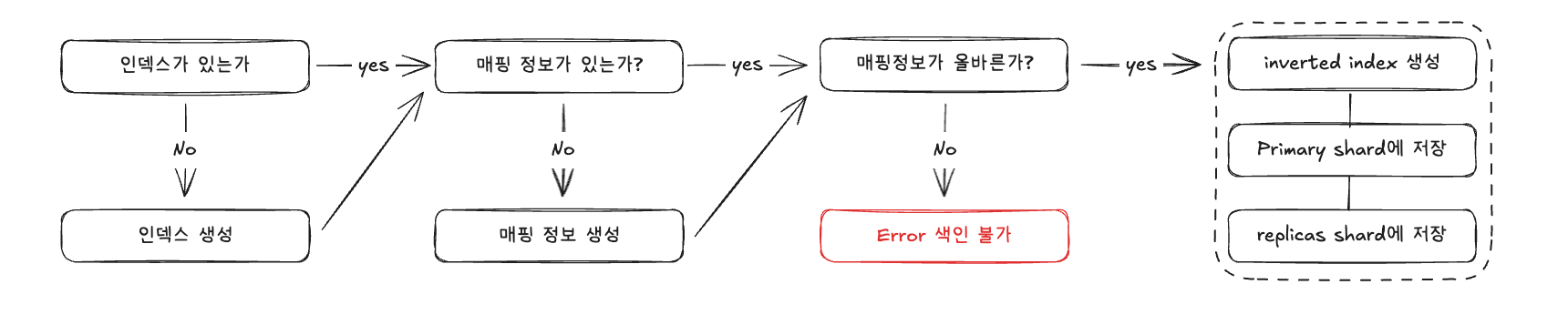
색인(Indexing) 과정
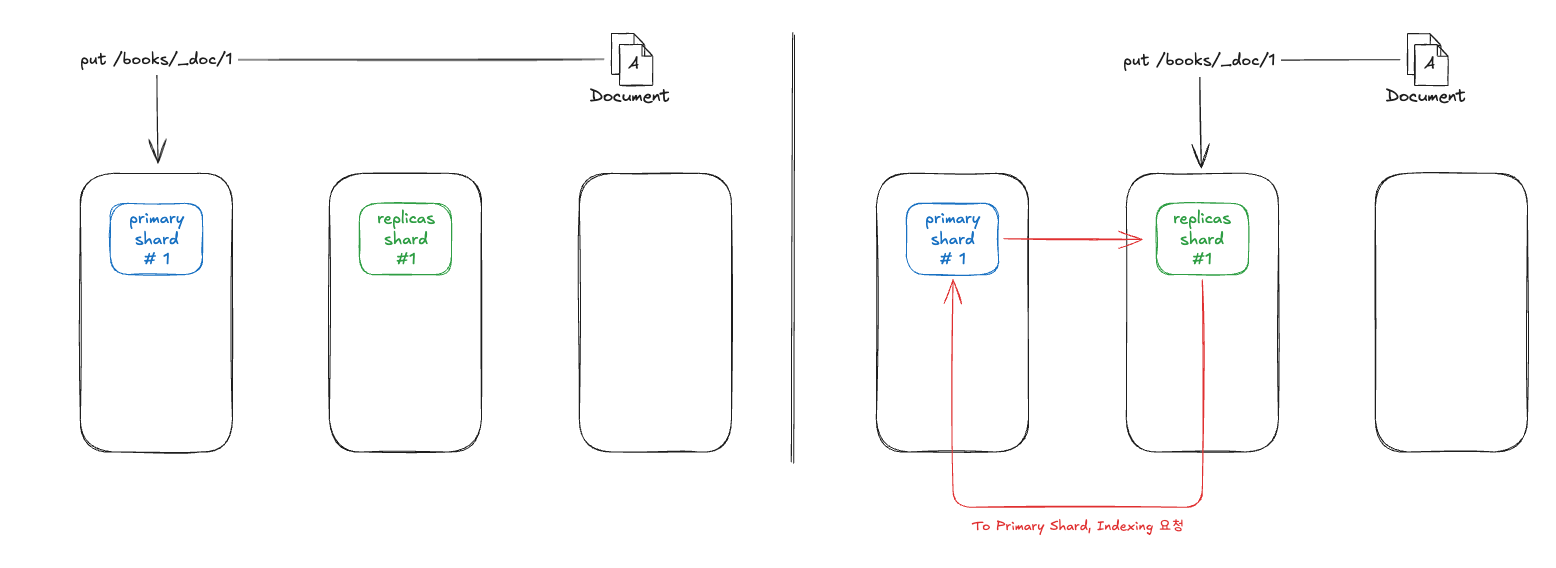
총 노드 3대의 클러스터에 Primary 샤드을 1대, Replicas 샤드를 1대로 설정해 두면 위 그림 처럼 설정 됩니다. 이전에 이론편에서 설명드리기는 했지만 Elasticsearch는 어떤 노드에 조회 및 색인 요청을 하던 동일한 결과 값을 보장합니다. 즉 1번 노드에 색인 요청을 해도 되고, 2번 노드, 3번 노드에 색인 요청을 해도 됩니다.
색인은 Primary 샤드에서 일어 납니다. 1번 노드에 색인 요청을 하게 된다면 Primary 샤드가 있기 때문에 바로 요청을 진행하게 됩니다. 반면 2번 노드에 색인 요청을 하게 된다면, Primary 샤드가 있는 노드에 다시 색인 요청을 하게 됩니다.
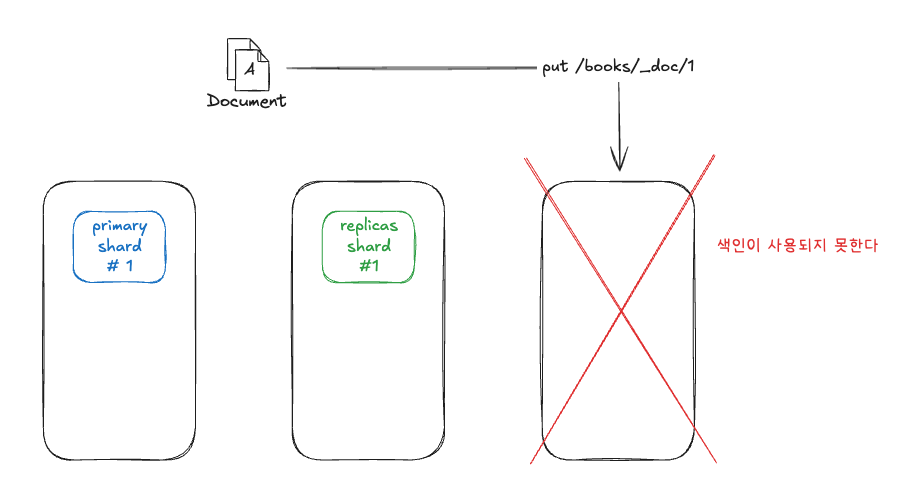
하지만 정말 큰 문제는 3번째 노드 입니다. 3번째 노드는 shard가 없기 때문에 Primary 저장도 Replicas 복제도 발생하지 않습니다. 즉 이러한 노드들은 클러스터로서의 이점을 전혀 살리지 못한 상황입니다.
적절한 수의 샤드 개수를 설정하는 것은 성능에 큰 영향을 미칩니다.

위 처럼 노드 구성을 했다면 이상적인 클러스터를 구성하게 된 것입니다.

엘라스틱서치는 문서의 _id(혹은 routing key)를 해시해 고정된 primary shard를 선택합니다. 예를 들어 _id=1은 primary shard #3에 매핑되고, 이후 해당 shard의 replica shard들로 전파됩니다. 이 때문에 특정 ID 문서는 항상 같은 샤드에 저장되며, 샤드 분포가 불균형하면 성능 문제가 생길 수 있습니다.
특정 _id가 항상 3번 샤드로 가는 것처럼 보일 수 있지만, 이는 단순히 해시 계산 결과일 뿐이며, 무조건 3번 샤드가 선택되는 것은 아닙니다. 엘라스틱서치의 라우팅은 샤드 단위로 결정됩니다. 샤드가 어떤 노드에 배치될지는 클러스터의 배치 정책에 따라 달라집니다. 만약 라우팅 키가 쏠려서 일부 샤드에만 데이터가 집중되면, 특정 샤드가 과부하되는 핫 샤드(Hot shard) 문제가 발생할 수 있습니다.
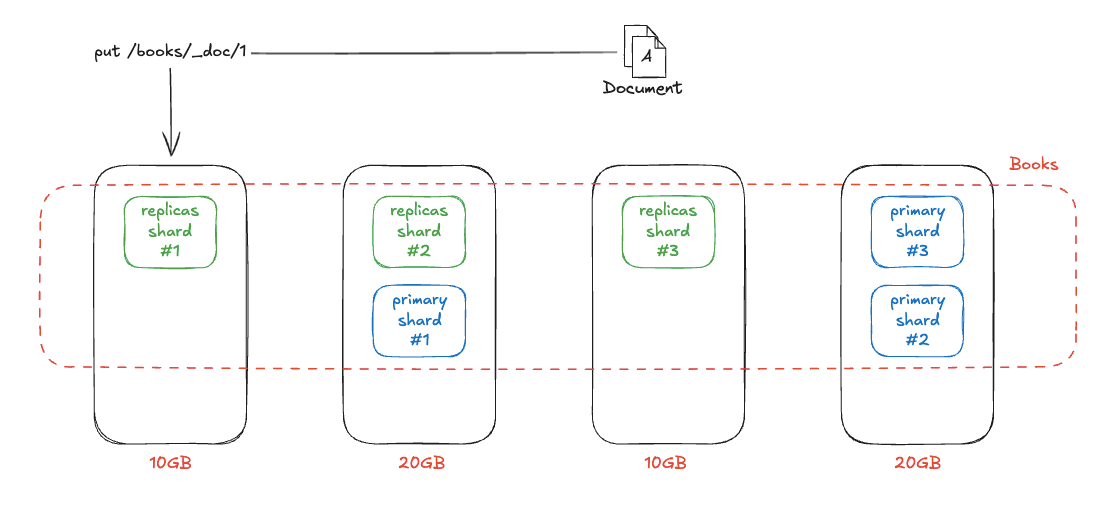
엘라스틱서치는 인덱스 생성 시점에 지정된 primary shard 개수에 따라 데이터를 분산합니다. 따라서 노드를 3대에서 4대로 늘리더라도 primary shard의 개수는 늘어나지 않으며, 단순히 샤드가 새 노드로 옮겨갈 뿐입니다. 이때 전체 샤드 수가 적으면 균등하게 나누는 것이 불가능해, 일부 노드에는 샤드가 1개만 배치되고 다른 노드에는 2개가 몰리는 식으로 불균형이 발생할 수 있습니다. 이런 경우 샤드가 균등하게 분배되지 않고 용량 불균형이 발생해, 각 노드의 디스크 사용량도 달라져 클러스터 운영에 부담이 될 수 있습니다. 즉, 리밸런싱 과정에서 문제가 발생할 수 있습니다.
'ElasticSearch' 카테고리의 다른 글
| ElasticSearch에 대해 알아보자 - (5) 트러블슈팅 : 문서 색인 불가 (1) | 2025.09.11 |
|---|---|
| ElasticSearch에 대해 알아보자 - (4) 트러블슈팅 : 클러스터의 상태 이상, 샤드 배치 이상 (0) | 2025.09.10 |
| ElasticSearch에 대해 알아보자 - (3) 검색 과정 이해하기 (0) | 2025.09.10 |
| ElasticSearch에 대해 알아보자 - (1) 용어 이해하기 (클러스터, 노드, 인덱스, 샤드, 매핑) (0) | 2025.09.05 |



