ElasticSearch란?
ElasticSearch는 검색, 데이터 분석에 최적화된 데이터베이스 입니다. 조금 더 어렵게 설명한다면 오픈 소스 분산, RESTful 검색 및 분석 엔진, 확장 가능한 데이터 저장소 및 벡터 데이터베이스이며, 루씬(Lucene- 자바 라이브러리)기반의 오픈소스 검색 엔진입니다. Json 기반의 문서를 저장하고 검색할 수 있으며 분석 작업도 가능 합니다.
ElasticSearch는 현업에서 크게 2가지 용도로 사용이 됩니다.
1. 데이터 수집 및 분석
Elasticsearch는 대규모 데이터(ex. 로그 등)를 수집 및 분석하는 데 최적화되어 있습니다. 주로 Elasticsearch(데이터 저장), Logstash(데이터 수집 및 가공), Kibana(데이터 시각화)를 같이 활용해 데이터를 수집 및 분석합니다.
2. 검색 최적화
Elasticsearch는 데이터가 많더라도 뛰어난 검색 속도를 가지고 있고, 오타나 동의어를 고려해서 유연하게 검색할 수 있는 기능을 가지고 있습니다. 쿠팡이나 배달의민족의 검색 기능도 전부 Elasticsearch를 활용해 구현되어있다.
ElasticSearch 특징
- 준실시간 검색 시스템으로 실시간이라고 생각될 만큼 색인된 데이터가 빠르게 검색 됩니다.
- 고가용성을 위한 클러스터 구성이 가능해서, 한 대 이상의 노드로 클러스터를 구성하여 높은 수준의 안정성을 달성하고 부하 분산이 가능합니다.
- 동적 스키마 생성으로 입력될 데이터들에 대해 미리 스키마를 정의하지 않아도 동적으로 스키마 생성이 가능합니다.
- Rest API 기반의 인터페이스를 제공하여 비교적 사용을 위한 진입 장벽이 낮습니다.
ElasticSearch 동작 방식
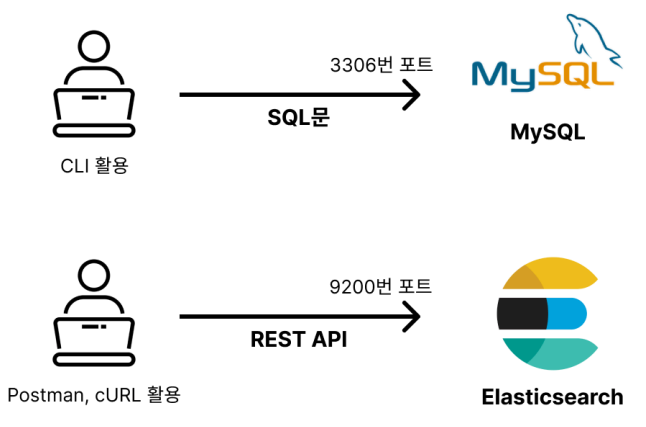
MySQL과 소통하려면 SQL문이라는 방식으로 통신해야 한다. 이와 비슷하게 Elasticsearch와 소통하려면 REST API라는 방식으로 통신해 야 한다.
MySQL
INSERT INTO users (name, email)
VALUES ('Alice', 'alice@example.com');
Elasticsearch
curl -X POST "localhost:9200/users/_doc" -H 'Content-Type: application/json' -d'
{
"name": "Alice",
"email": "alice@example.com"
}'
ElasticSearch 클러스터
ElasticSearch 클러스터는 대규모 데이터를 분산 환경에서 빠르고 안정적으로 검색하고 분석할 수 있도록 구성된 ElasticSearch 노드들의 집합을 의미합니다. 기본적으로 단일 노드에서도 실행할 수 있지만, 실제 서비스 환경에서는 고가용성과 확장성을 위해 클러스터 구조로 운영하는 경우가 많습니다.
ElasticSearch 클러스터 특징
ElasticSearch도 여러 대의 노드들이 각자의 역할을 바탕으로 연결되어 하나의 시스템처럼 동작하게 되어 있습니다. 따라서 어떤 노드에 어떤 요청을 해도 동일한 응답을 줍니다.
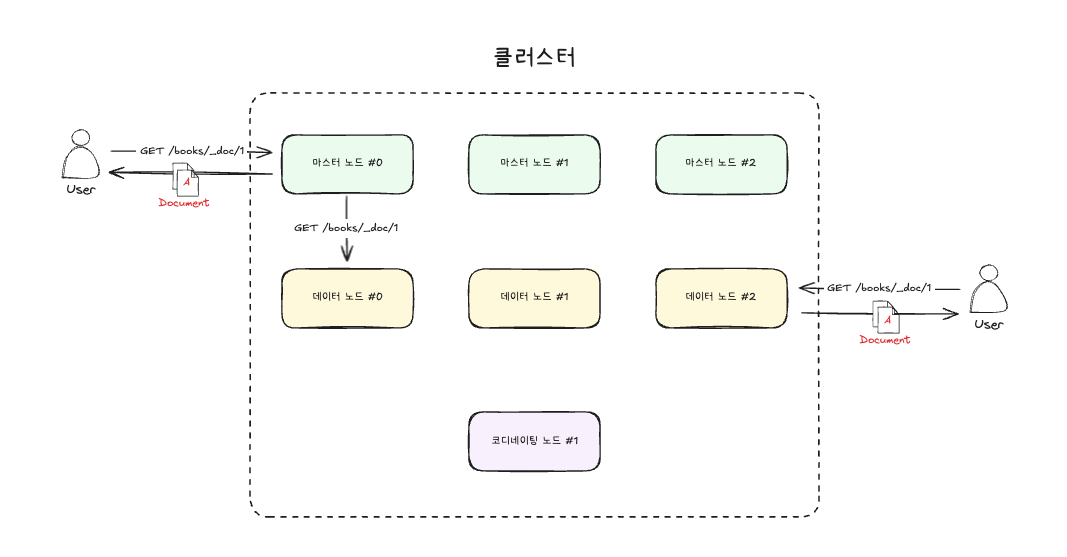
그림을 자세히 보면, 마스터 노드에게 문서 조회 요청을 하면 'A document'를 반환합니다. 또한 데이터 노드에게 동일하게 문서 조회 요청을 하면 데이터 노드 역시 'A document'를 반환합니다. 즉 어느 노드에 요청을 해도 동일한 응답을 하게 됩니다.
각 노드들은 다음과 같은 역할을 합니다.
- 마스터 노드 - 클러스터 상태 관리 및 메타데이터 관리
- 데이터 노드 - 문서 색인 및 검색 요청 관리
- 코디네이팅 노드 - 검색 요청 처리
- 인제스트 노드 - 색인되는 문서의 데이터 전처리
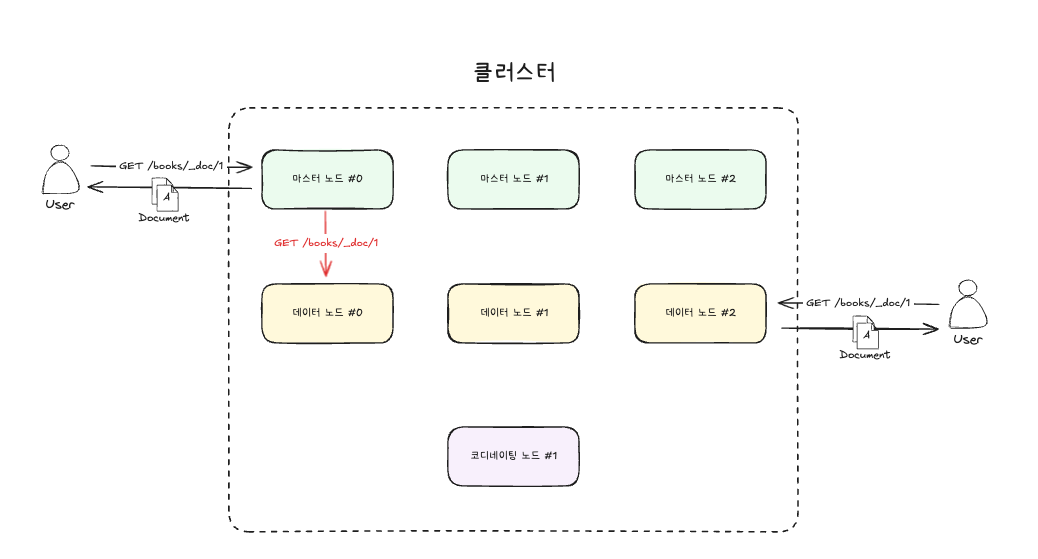
그림을 보면 마스터 노드는 클러스터의 상태를 관리하는 노드 입니다. 하지만 검색 요청을 해도 잘 처리합니다. 데이터 노드를 곧 바로 검색하는 것과 동일한 응답(A document)을 반환합니다. ElasticSearch 클러스터의 특징이니깐요.
그런데 굳이 마스터 노드에 조회 해야 할까요? 그냥 데이터 노드를 곧 바로 조회 하면 더 좋지 않을까요?

코디네이팅 노드는 검색 요청 처리하는 노드입니다. 하지만 색인을 요청해도 잘 동작 합니다. 또한 원래 색인 요청은 데이터 노드가 담당하기 때문에 데이터 노드에 곧 바로 요청 해도 잘 동작 합니다.
그러면 굳이 코디네이팅 노드에 색인 요청을 해야 할까요? 그냥 데이터 노드에 곧 바로 색인 요청을 하면 더 좋지 않을까요?
→ 네! 각각의 노드가 본연의 역할에 충실할 수 있도록 구성하는 것이 중요합니다. 물론 클러스터기 때문에 어떤 노드에 요청을 하든 동일한 결과를 보장합니다.

따라서 로드밸런서의 EndPoint를 구성해서 검색과 색인 요청에 대한 API를 제공하면, 로드밸러서를 통해 자동으로 적절한 역할의 노드에 접근 하게 됩니다.
ElasticSearch 인덱스
인덱스는 문서가 저장되는 논리적인 공간 입니다. 따라서 문서를 저장하기 위해서는 반드시 인덱스가 존재해야 합니다. 인덱스를 설계하는 것이 ElasticSearch를 사용하기 위해 고려해야 하는 첫 단계 입니다.
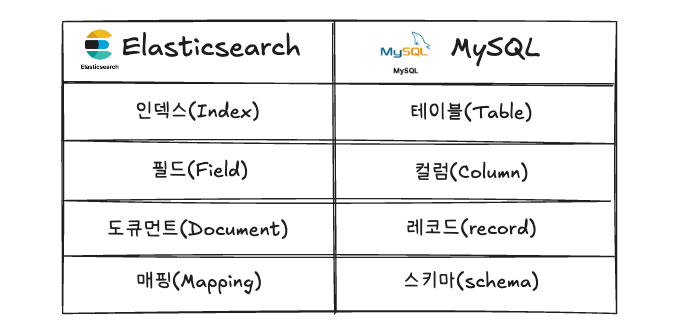
먼저 ElasticSearch와 RDBMS를 비교해 보면 표처럼 비교할 수 있습니다.
인덱스(index) 설계

인덱스는 설계에 따라서 문서의 구조와 검색 쿼리가 달라지기 때문에, 사용 패턴과 문서의 특성에 따라 설계 해야 합니다.
| 케이스 | 장점 | 단점 |
| 하나의 인덱스를 사용 | 관리해야 할 인덱스의 수가 적다 | 쿼리와 문서의 구조가 복잡해 진다. |
| 여러개의 인덱스를 사용 | 경우에 따라 최적화된 쿼리와 문서 구조 사용이 가능하다 | 관리해야 할 인덱스가 많아 진다. |
ElasticSearch Shard
샤드(shard) 란?
샤드는 인덱스에 색인되는 문서가 저장되는 공간입니다. 하나의 인덱스는 반드시 하나 이상의 샤드를 가져야 합니다.

샤드의 종류
- 프라이머리 샤드 : 문서가 저장되는 원본 샤드, 색인과 검색 성능에 모두 영향을 줌
- 레플리카 샤드 : 프라이머리 샤드의 복제 샤드, 검색 성능에 영향을 줌, 플라이머리 샤드에 문제가 생기면 레플리카 샤드가 프라이머리 샤드로 승격
샤드 라우팅
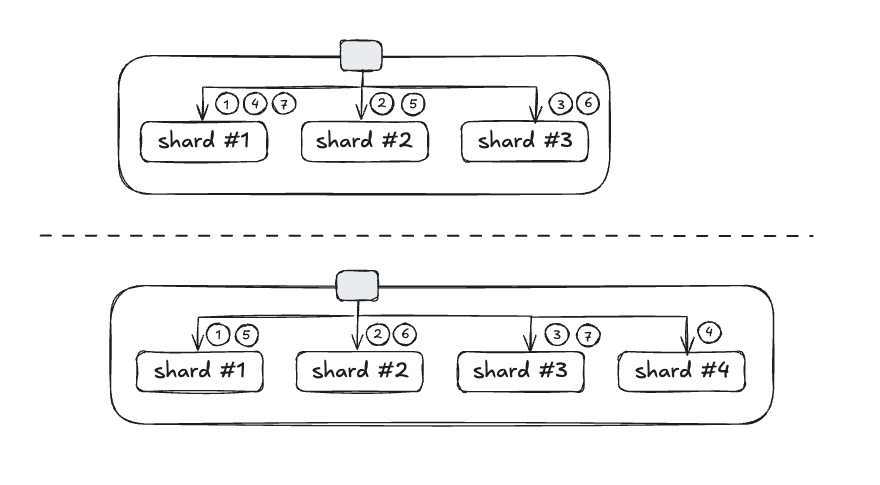
샤드의 라우팅은 샤드에 문서가 저장되는 방법입니다. 일반적으로 문서들은 0~2번 까지의 샤드에 고르게 저장 됩니다. 그래서 샤드의 개수가 바뀐다면 문서가 저장되는 규칙이 완전히 바뀌기 때문에, 인덱스 생성 이후 프라이머리 샤드 개수 변경은 불가합니다. 따라서 인덱스를 생성할 때 프라이머리 샤드의 개수를 설정하는 건 매우 중요합니다.
ElasticSearch Mapping
매핑(mapping) 이란?
ElasticSearch에서 매핑(mapping)은 데이터가 저장될 때 문서(Document)의 필드와 타입을 정의하는 방식을 의미합니다. 쉽게 말하면, 관계형 데이터베이스에서 스키마(schema)에 해당한다고 볼 수 있습니다. ElasticSearch는 스키마리스는 아니지만 미리 정의하지 않아도 됩니다.

- 매핑은 한 번 정의되면 변경이 어렵습니다. (특히 필드 타입은 수정 불가)
- 매핑을 잘못 정의하면 나중에 검색이나 집계 성능에 큰 영향을 미칠 수 있습니다.
- 그래서 대규모 서비스에서는 매핑 설계가 인덱스 설계의 핵심이라고 할 수 있습니다.
매핑의 종류
- 동적 매핑 : 처음 색인되는 문서를 바탕으로 매핑 정보를 ElasticSearch가 동적으로 생성,
- 정적 매핑 : 문서의 매핑 정보를 미리 정의
동적 매핑
동적 매핑은 어떤 문서가 색인될지 스키마를 미리 정의하지 않아도 됩니다. 또한 동적 매핑에 의해 매핑 정보가 생성된 후에는 타입이 맞지 않을 경우 파싱에러가 발생 합니다.
정적 매핑
어떤 문서가 색인될지 스키마를 미리 정의 합니다.
- 정적 매핑은 문서의 필드들이 가지는 값에 따라 타입을 지정해 줄 필요가 있을 때 적합합니다.
- 불필요한 색인이 필요하지 않게 하기 위할 때도 적합합니다.
'ElasticSearch' 카테고리의 다른 글
| ElasticSearch에 대해 알아보자 - (5) 트러블슈팅 : 문서 색인 불가 (1) | 2025.09.11 |
|---|---|
| ElasticSearch에 대해 알아보자 - (4) 트러블슈팅 : 클러스터의 상태 이상, 샤드 배치 이상 (0) | 2025.09.10 |
| ElasticSearch에 대해 알아보자 - (3) 검색 과정 이해하기 (0) | 2025.09.10 |
| ElasticSearch에 대해 알아보자 - (2) 색인 과정 이해하기 (0) | 2025.09.09 |



