트러블 슈팅 : 클러스터의 상태 이상
엘라스틱서치를 운영하다 보면 클러스터 상태가 항상 Green으로 유지되지 않고, Yellow 혹은 Red로 표시되는 경우가 있습니다. 이번 글에서는 이러한 상태들이 의미하는 바와, 실제 트러블슈팅 접근 방식을 정리해 보겠습니다.
클러스터 상태 색상 의미

- Green
- 모든 Primary 샤드와 Replica 샤드가 정상적으로 각 노드에 배치된 상태
- 색인 및 검색 모두 정상
- Yellow
- Primary 샤드는 정상 동작하지만 일부 Replica 샤드가 배치되지 않은 상태
- 색인에는 문제가 없지만, 장애 상황에 대비한 복제본이 없으므로 검색 성능 및 안정성에 영향을 줄 수 있음
- Red
- 일부 Primary 샤드가 배치되지 않은 상태
- 색인과 검색 모두에 영향을 주며, 문서 유실 가능성이 있음
즉, Green이 정상 상태이고, Yellow는 주의가 필요하며, Red는 즉각 조치해야 하는 장애 상태입니다.
1. 문제 상황 파악
클러스터가 Yellow나 Red 상태일 때는, 단순히 “문제가 있다”라고만 보기보다는 정확히 어떤 인덱스와 샤드가 영향을 받고 있는지를 먼저 확인해야 합니다.
1-1. 인덱스 상태 확인
클러스터 전체 상태가 Yellow나 Red일 경우, 우선 어떤 인덱스가 문제를 일으키고 있는지 확인해야 합니다. 이를 위해 _cat/indices API를 사용할 수 있습니다.

# 클러스터 내 인덱스 상태 확인
curl -X GET "localhost:9200/_cat/indices" | grep -i red
red open access_log-2022-11-17 siILpfKwSxWygopwN1wb_g 5 1 ....
red open access_log-2022-11-19 eDnJJdIdRfKQjGpOwTdAgA 5 1 ....
red open access_log-2022-11-20 1pYOZQhNSq2joUD-RcQiHQ 5 1 ....
위 결과를 해석하면, access_log 인덱스가 여러 날짜별로 Red 상태임을 알 수 있습니다. 이는 해당 인덱스의 프라이머리 샤드가 할당되지 않은 상태를 의미하며, 따라서 이 인덱스에 저장된 데이터는 정상적으로 조회할 수 없습니다.
문제 인덱스를 확인한 뒤에는, 해당 인덱스의 샤드가 왜 할당되지 않았는지를 구체적으로 파악해야 합니다. Elasticsearch에서는 _cat/shards API를 사용하여 샤드별 상태와 할당 실패 사유를 조회할 수 있습니다.
curl -X GET "localhost:9200/_cat/shards?h=idx,sh,pr,st,docs,unassigned.reason" | grep -iv started
위 명령어는 각 인덱스의 샤드 상태를 보여주되, started 상태가 아닌 것들만 필터링하여 확인할 수 있도록 구성했습니다.
index shard prirep state docs unassigned.reason
access_log-2022-11-17 1 p UNASSIGNED .. NODE_LEFT
access_log-2022-11-17 2 p UNASSIGNED .. NODE_LEFT
2. 문제 해결 방법
위 결과에서 볼 수 있듯이, access_log-2022-11-17 인덱스의 샤드가 UNASSIGNED 상태로 남아 있습니다. unassigned.reason 값이 NODE_LEFT로 표시되었는데, 이는 해당 샤드를 보유하던 노드가 클러스터에서 이탈하면서 샤드가 할당되지 못한 상태임을 의미합니다. 즉, 단순히 클러스터가 Red라는 현상만 보는 것이 아니라, 구체적으로 어떤 샤드가 어떤 이유로 할당되지 않았는지 확인할 수 있습니다.
NODE_LEFT는 일반적으로 다음과 같은 상황에서 발생할 수 있습니다.
- 노드 장애
데이터 노드가 비정상 종료되거나 네트워크 단절이 발생한 경우. - 노드 제거
운영 중 노드를 수동으로 제거하거나 클러스터 구성이 변경된 경우. - 디스크/리소스 부족
노드가 남아있지만, 디스크 용량 부족이나 샤드 할당 제한 설정으로 인해 샤드가 재할당되지 못하는 경우.
3. 정리
- 클러스터의 상태가 Yellow 혹은 Red 일 때는 어떤 인덱스들이 영향을 받고 있는지를 파악해야 합니다.
- 영향을 받는 인덱스들 중 어떤 샤드들에 어떤 문제가 있는지 파악합니다.
- 클러스터의 상태가 Yellow 혹은 Red 이지만 경우에 따라서는 장애 상황이 아닐 수 있기 때문에 정확한 파악이 중요합니다.
트러블 슈팅 : 샤드 배치가 되지 않는 경우
운영 환경에서 Elasticsearch를 사용하다 보면 새로운 인덱스 생성이 실패하거나, 샤드가 정상적으로 배치되지 않는 문제를 마주할 수 있습니다.
1. 문제 상황 파악
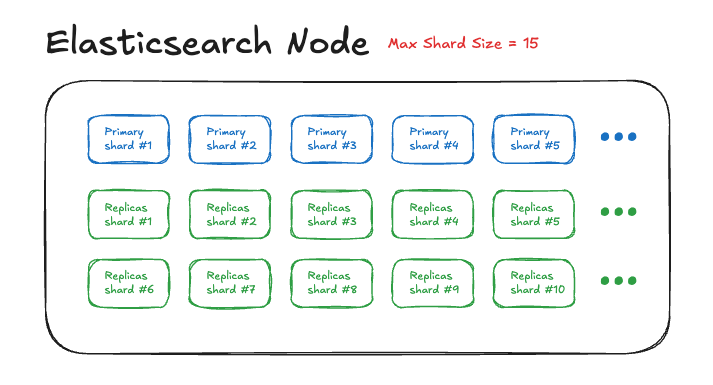
Elasticsearch의 데이터 노드에는 노드 당 가질 수 있는 샤드의 개수에 제한이 있습니다. 이 제한을 초과하면 새로운 샤드를 생성할 수 없고, 그에 따라 인덱스 생성도 불가능해집니다. 즉, 아무리 새로운 데이터를 넣으려 해도 클러스터가 더 이상 샤드를 수용하지 못하는 상황이 발생하게 됩니다.
원인 : cluster.max_shards_per_node
Elasticsearch는 cluster.max_shards_per_node 설정값을 통해 노드 당 샤드 개수 제한을 관리합니다. 기본값은 1,000개이며, 이 값을 초과하는 순간부터는 샤드가 더 이상 배치되지 않습니다.
예를 들어, 다음과 같은 인덱스 설정을 사용한다고 가정해 봅시다.
{
"index.number_of_shards": 5,
"index.number_of_replicas": 1
}
- 인덱스 하나당 10개의 샤드(프라이머리 5개 + 레플리카 5개)가 생성됩니다.
- 매일 새로운 인덱스를 생성한다면, 1년간 약 3,650개의 샤드가 쌓이게 됩니다.
- 데이터 노드가 3대라면, 각 노드가 약 1,217개의 샤드를 가져야 하는 상황이 되어 기본 제한(1,000)을 초과하게 됩니다.
2. 문제 해결 방법
문제를 해결하기 위한 방법은 크게 세 가지가 있습니다.
1. 데이터 노드 증설
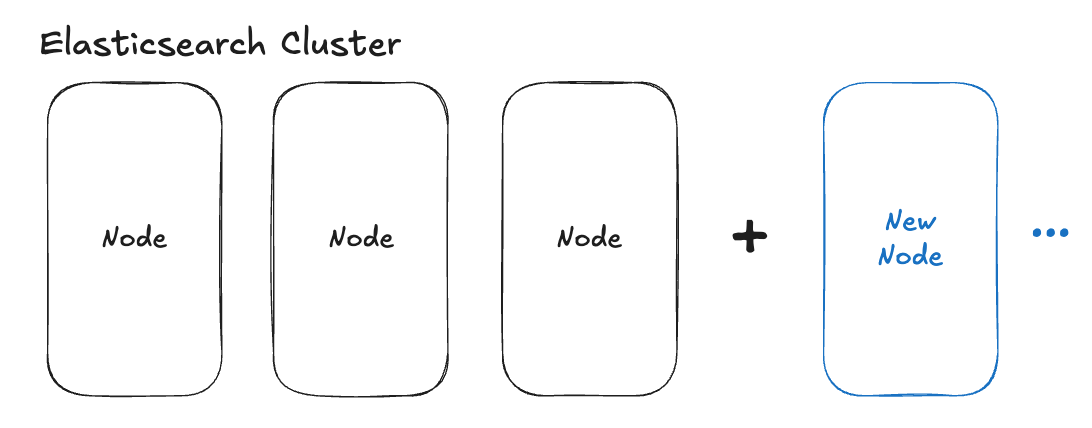
노드를 늘리면 샤드가 분산되어 노드 당 샤드 수가 줄어듭니다. 가장 직관적이고 안정적인 방법이지만, 인프라 자원이 필요하다는 점에서 비용 부담이 있을 수 있습니다.
2. 인덱스 설정 변경
샤드 개수를 줄이는 방식으로도 대응할 수 있습니다.

예를 들어 위 설정을 다음과 같이 조정한다면
{
"index.number_of_shards": 3,
"index.number_of_replicas": 1
}
- 하루에 생성되는 샤드 수: 6개
- 1년간 생성되는 샤드 수: 2,190개
- 데이터 노드 3대일 경우, 노드당 약 730개 샤드 보유 → 안전하게 제한 이내 유지.
이는 가장 권장되는 접근 방식입니다.
3. cluster.max_shards_per_node 값 변경
설정값 자체를 늘리는 방법도 있습니다.

PUT /_cluster/settings
{
"persistent": {
"cluster.max_shards_per_node": "3000"
}
}
이 방법으로 일시적으로는 문제를 해결할 수 있지만, 노드에 과도한 샤드가 몰리면서 성능 저하, 메모리 부족, GC 지연 등 다양한 사이드 이펙트가 발생할 수 있습니다. 따라서 권고되지 않습니다.
3. 정리
- Elasticsearch에는 노드 당 샤드 개수 제한(기본 1,000개) 이 존재합니다.
- 인덱스가 쌓이다 보면 이 한도를 초과해 샤드 배치가 불가능해질 수 있습니다.
- 해결 방법으로는 데이터 노드 증설, 인덱스 샤드 수 축소가 가장 안정적이며, cluster.max_shards_per_node 변경은 최후의 수단으로만 고려해야 합니다.
'ElasticSearch' 카테고리의 다른 글
| ElasticSearch에 대해 알아보자 - (5) 트러블슈팅 : 문서 색인 불가 (1) | 2025.09.11 |
|---|---|
| ElasticSearch에 대해 알아보자 - (3) 검색 과정 이해하기 (0) | 2025.09.10 |
| ElasticSearch에 대해 알아보자 - (2) 색인 과정 이해하기 (0) | 2025.09.09 |
| ElasticSearch에 대해 알아보자 - (1) 용어 이해하기 (클러스터, 노드, 인덱스, 샤드, 매핑) (0) | 2025.09.05 |



