Tasklet 지향 처리
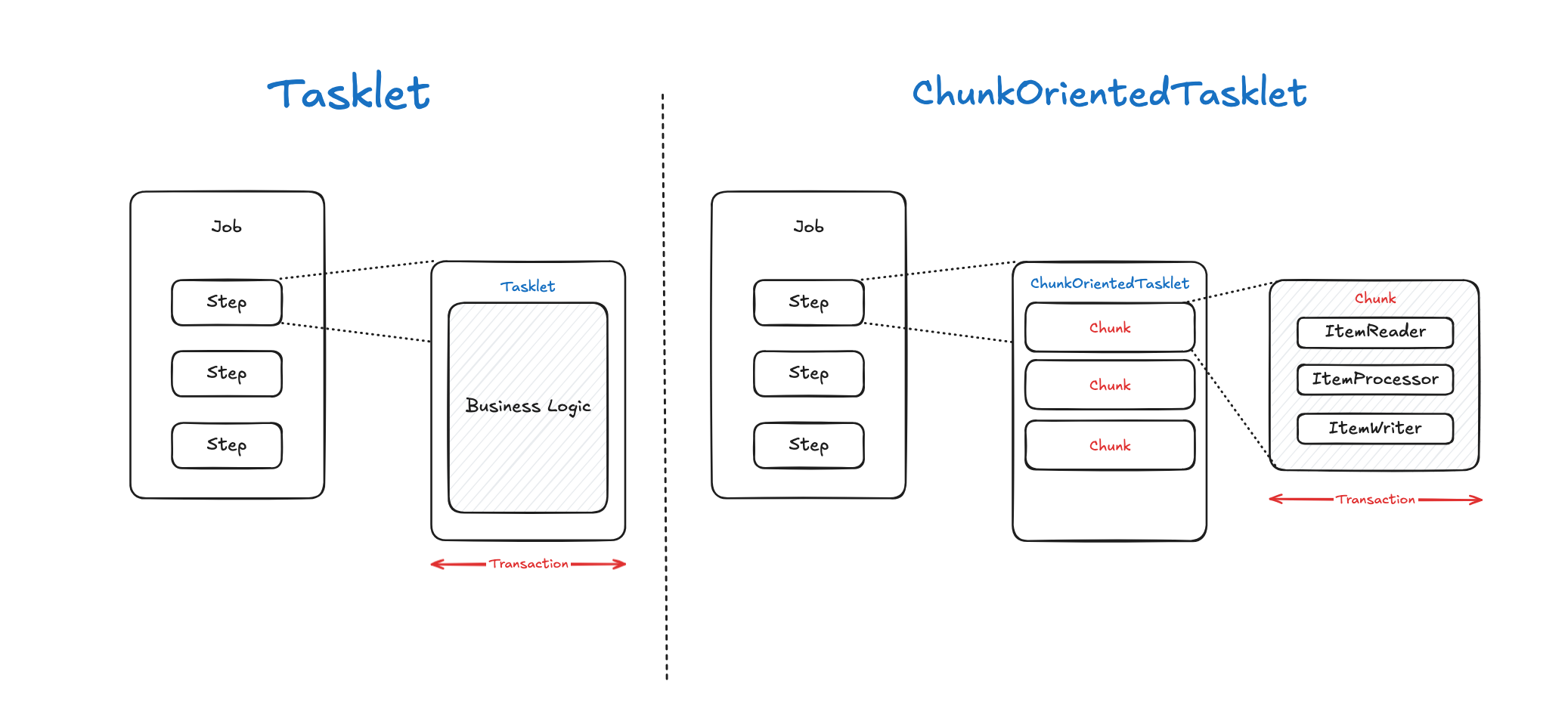
앞서 설명했듯, Tasklet 지향 처리 모델은 Spring Batch에서 가장 기본적인 Step 구현 방식으로 단순한 작업을 할때 많이 사용이 됩니다.
Tasklet은 보통 다음과 같은 단순한 작업이나 유틸성 작업에 많이 사용이 됩니다.
- 불필요한 로그 파일 삭제
- 오래된 파일 아카이브
- 단순 알림 혹은 메일 발송
- 단순하게 외부 API호출 후 결과를 저장하거나 로깅하는 경우
즉, 단순한 비즈니스 로직 실행에서 많이 사용이 됩니다.
Tasklet 구현 - RepeatStatus를 잘 사용하자
Tasklet 구현 코드를 먼저 살펴봅시다.
코드1) 내부에 while()문을 반복한 경우
public class taskletOriented implements Tasklet {
private final int target = 10;
private int count = 0;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
while (count < target) {
log.info("프로세스 진행중... ({}/{})", count, target);
count++;
}
log.info("작업 완료.");
return RepeatStatus.FINISHED; // 모든 프로세스 종료 후 작업 완료
}
}
코드2) RepeatStatus.CONTINUED를 사용해서 execute()를 반복한 경우
public class taskletOriented implements Tasklet {
private final int target = 10;
private int count = 0;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
count++;
log.info("프로세스 진행중... ({}/{})", count, target);
if (count >= target) {
log.info("작업 완료.");
return RepeatStatus.FINISHED; // 모든 프로세스 종료 후 작업 완료
}
return RepeatStatus.CONTINUABLE; // 아직 더 종료할 프로세스가 남아있음
}
}
둘 다 로그를 10번 출력하는 코드입니다. 하지만 RepeatStatus를 사용한 차이가 있다는 것을 알 수 있습니다.
- RepeatStatus.FINISHED
- Step의 처리가 성공이든 실패든 상관없이 해당 Step이 완료되었음을 의미합니다.
- 더 이상 반복할 필요가 없음으로 다음 스텝으로 넘어갑니다.
- RepeatStatus.CONTINUED
- 아직 작업이 진행중인 상태로, 추가적인 실행이 필요하다는 것을 의미합니다.
그렇다면 왜? 굳이 RepeatStatus.CONTINUED를 사용한 걸까요?

Spring Batch는 Tasklet의 execute()를 호출할 때 마다 새로운 트랜잭션을 시작하고, RepeatStatus가 반환되면 트랜잭션을 커밋 합니다. 내부에 반복문을 사용한 경우는 모든 작업이 하나의 트랜잭션 안에서 실행되는 반면, RepeatStatus.CONTINUED를 사용한 코드2는 execute마다 트랜잭션이 적용되기 때문에 작은 트랜잭션들로 나누어 안전하게 처리 할 수 있습니다.
Chunk 지향 처리
chunk(청크)는 데이터를 일정 단위로 쪼갠 덩어리를 말합니다. Spring Batch에서는 청크를 데이터 기반 처리 방식이라고 부르는데, 읽고, 처리하고, 쓰는 작업을 일정 크리로 나눈 데이터 덩어리를 대상으로 하기 때문입니다.
1,000,000(백만)건의 데이터를 처리해야 할때, 100건씩 청크 단위로 처리한다면 10,000번만 반복하면 됩니다.
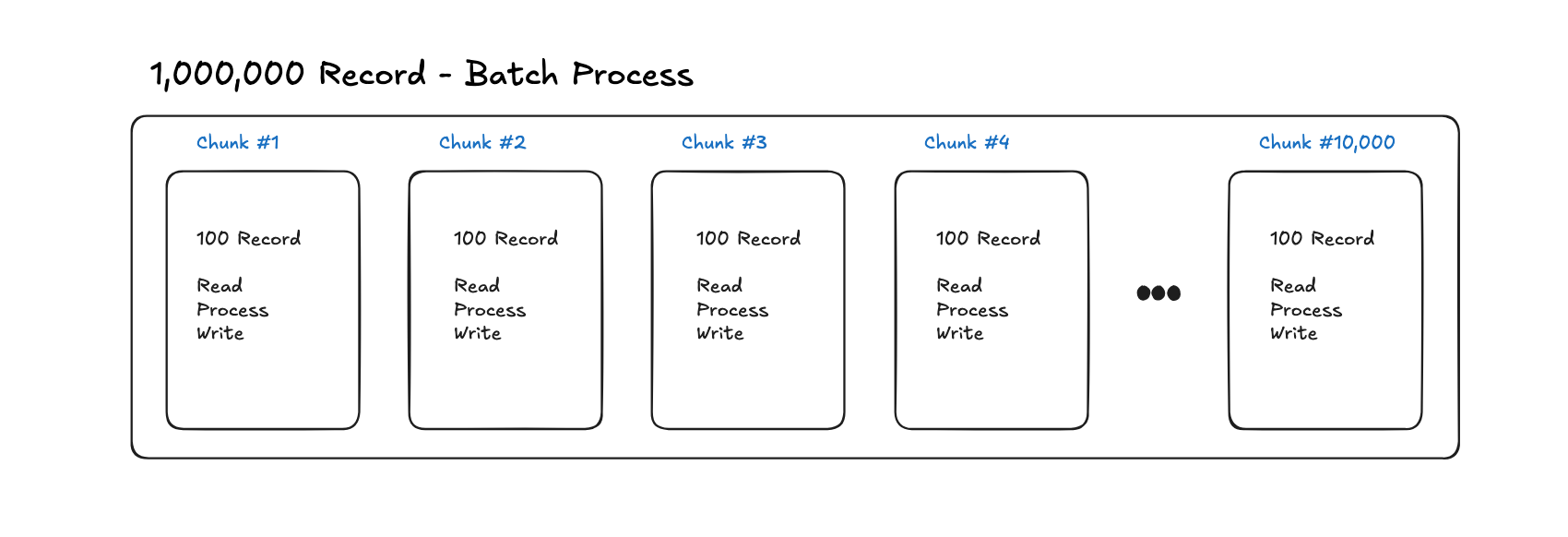
이렇게 청크를 나누는 이유는 대량의 데이터를 한 번에 메모리에 불러오고, 처리하고, 저장하다면 메모리가 터지거나, DB가 과부하로 죽을 가능성이 큽니다.
Chunk 처리의 장점
1. 메모리를 작게 사용할 수 있습니다.
작은 단위의 데이터를 DB에서 조회한다면 당연히 적은 메모리를 사용하고 안정적으로 처리할 수 있습니다.
2. 트랜잭션을 작게 처리하여, 전체 롤백을 방지 할 수 있습니다.
청크는 청크 단위로 트랜잭션이 적용 되기 때문에, 중간에 오류가 발생하더라도 해당 청크를 제외한, 이전에 작업이 완료된 청크는 데이터를 성공적으로 커밋하고 반영할 수 있습니다.
적절한 Chunk 사이즈는?
적절한 청크 사이즈는 비즈니스 로직에 따라 당연히 다르다.
청크 사이즈가 클 때
- 청크 크기 만큼 많은 메모리가 한번에 로드 된다.
- 트랜잭션의 범위가 커지므로, 장애로 인해 롤백 발생시 롤백되는 데이터 양도 많아 진다.
청크 사이즈가 작을 때
- 트랜잭션의 경계가 작아져서 문제 발생시 롤백되는 데이터가 최소화 된다.
- 청크 사이즈가 작은 만큼 데이터베이스 I/O도 자주 발생한다. (데이터 베이스 연결이 10ms가 소요 된다면 100만건의 데이터는 약 2.77시간이 소요된다.)
Chunk의 3대장 - Read, Process, Write

1. ItemReader
ItemReader는 데이터를 조회하는 부분 입니다. ItemReader는 read()메서드를 통해 아이템을 하나씩 반환 합니다. 여기서 아이템은 데이터베이스의 한 행(row)와 같은 것을 의미합니다. 즉, 데이터를 데이터 소스(DB, File, Message 등)에서 하나씩 순차적으로 읽어 옵니다.
2. ItemProcessor
ItemProcessor은 데이터를 가공하는 부분 입니다. ItemProcessor은 반드시 구성되어야 하는 것은 아닙니다. 경우에 따라 Read, Write만 수행하고 Process는 생략을 해도 됩니다.
3. ItemWriter
ItemWriter는 데이터를 한 건씩 쓰지 않고, Chunk 단위로 묶어서 한번에 데이터를 씁니다. ItemReader와 ItemProcessor는 아이템을 하나씩 반환하고 입력받는 것과 달리, ItemWriter는 청크 단위로 처리합니다.
Reader-Processor-Writer 동작원리
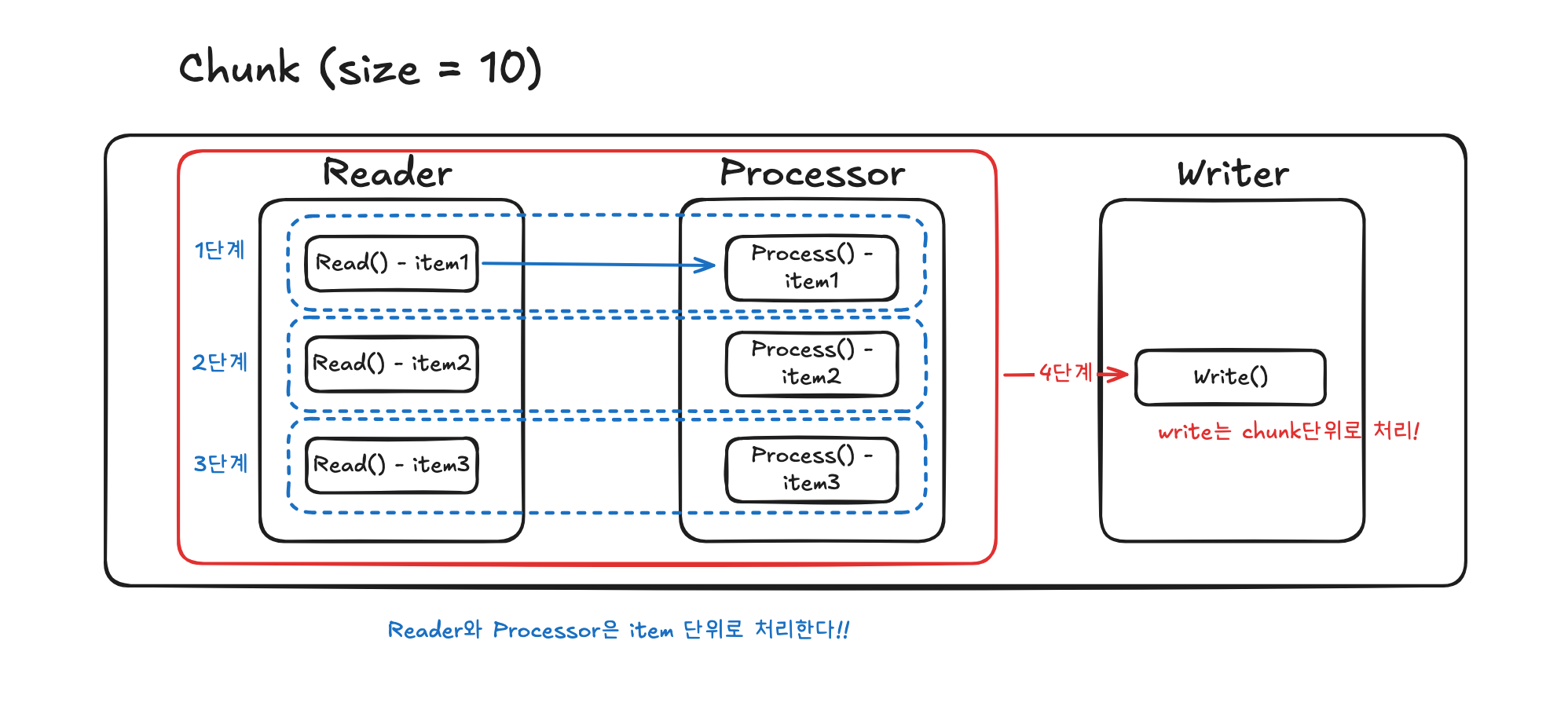
- Item #1 read() > process()
- Item #2 read() > process()
- Item #3 read() > process()
- Item #4 read() > process()
- ... 반복
- Item10 read() > process()
- Chunk #1 write()
Reader와 Processor은 item 단위로 처리된다. 반면 Writer는 청크 단위(item 10개) 단위로 처리 됩니다. Reader-Processor-Writer가 한 묶음으로 반복 되는 것으로 잘못 이해하면 안 됩니다.
Reader-Processor-Writer 패턴의 장점
1. 완벽한 책임 분리
각 컴포넌트는 자신의 역할만 수행할 수 있습니다.. ItemReader는 읽기, ItemProcessor는 가공, ItemWriter는 쓰기에만 집중할 수 있기 때문에 코드는 명확해지고 유지보수는 간단해 집니다.
2. 재사용성 극대화
컴포넌트들은 독립적으로 설계되어 있어 어디서든 재사용이 가능합니다. 새로운 배치를 만들 때도 기존 컴포넌트들을 조합해서 빠르게 구성할 수 있습니다.
3. 높은 유연성
요구사항이 변경되어도 해당 컴포넌트만 수정하면 됩니다. 데이터 형식이 바뀌면 ItemProcessor만, 데이터 소스가 바뀌면 ItemReader만 수정하면 됩니다.
4. 대용량 처리의 표준
데이터를 다루는 배치 작업은 결국 '읽고-처리하고-쓰는' 패턴을 따르는데, Spring Batch는 이 패턴을 완벽하게 구조화 했습니다.
'Batch' 카테고리의 다른 글
| Spring Batch에 대해 알아보자 - (2) Step, StepExecution, StepContribution (0) | 2025.08.29 |
|---|---|
| Spring Batch에 대해 알아보자 - (1) Job, JobInstance, JobParameter, JobExecution (0) | 2025.08.29 |

