들어가기 앞서
이전 포스팅에서는 카프카의 브로커, 클러스터 개념에 대해 간단히 알아보았습니다. 이번 포스팅에서는 카프카의 프로듀서와 컨슈머에 대해 공부할 예정입니다. 이전 포스팅에서도 언급하였지만 아래 책을 활용하여 공부하고 있으며, 3장 카프카 기본 개념 설명 부분에 해당하는 글입니다.
https://www.yes24.com/product/goods/99122569
아파치 카프카 애플리케이션 프로그래밍 with 자바 - 예스24
아파치 카프카 애플리케이션 개발을 위한 「실전 가이드」아파치 카프카란 무엇일까? 카프카 애플리케이션은 어떻게 만들까? 데이터 파이프라인을 만들기 위해 어떤 카프카 라이브러리를 사용
www.yes24.com
프로듀서(Producer)
Kafka에서 프로듀서(Producer)는 데이터를 생성하여 카프카 브로커의 특정 토픽과 파티션에 전송하는 역할을 담당합니다. 프로듀서는 전송 대상이 되는 파티션의 리더를 보유한 브로커와 직접 통신하며 데이터를 전달합니다.
프로듀서가 전송하는 데이터는 내부적으로 직렬화(Serialization) 과정을 거치게 됩니다. 직렬화란 자바 또는 외부 시스템에서 사용할 수 있도록 데이터를 바이트 배열 형태로 변환하는 기술을 의미합니다. 이 과정을 통해 자바의 기본형, 참조형은 물론 이미지나 동영상과 같은 바이너리 데이터도 Kafka를 통해 전송할 수 있게 됩니다.
프로듀서의 데이터 전송 흐름
Kafka 프로듀서는 데이터를 전송할 때 내부적으로 다음과 같은 주요 단계를 거칩니다.
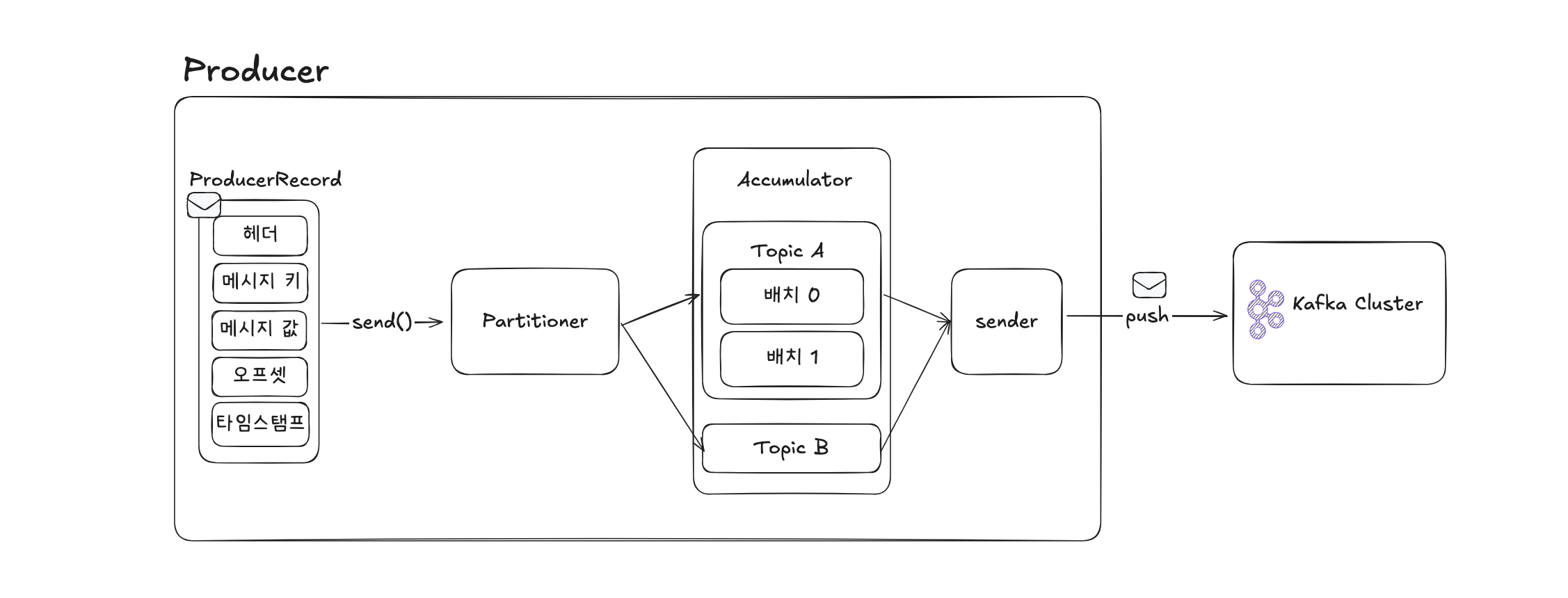
- ProducerRecord 생성
데이터 전송 시에는 ProducerRecord 객체를 생성합니다. 이 객체에는 필수 파라미터인 토픽명과 메시지 값 외에도, 파티션 번호, 메시지 키, 타임스탬프 등 다양한 속성을 지정할 수 있습니다. 레코드의 타임스탬프는 기본적으로 브로커 시간으로 설정되지만, 필요에 따라 메시지 생성 시간이나 그 이전, 이후로도 지정할 수 있습니다. - 파티셔너(Partitioner)
KafkaProducer의 send() 메서드가 호출되면, 데이터는 파티셔너를 통해 어느 파티션에 전송될지 결정됩니다. 별도로 지정하지 않으면 DefaultPartitioner가 기본 파티셔너로 사용됩니다. 파티셔너는 메시지 키가 있는 경우 해당 키의 해시 값을 기준으로 파티션을 결정합니다. - 어큐뮬레이터 및 배치 처리
파티셔너에 의해 분류된 레코드는 어큐뮬레이터(Accumulator) 라는 버퍼에 잠시 저장됩니다. 이 버퍼에 일정량 이상의 데이터가 쌓이면 이를 배치(batch) 단위로 묶어 브로커로 전송합니다. 이러한 배치 처리는 프로듀서의 처리량을 크게 향상시키는 데에 매우 효과적입니다.
메시지 키를 가진 데이터를 전송할때
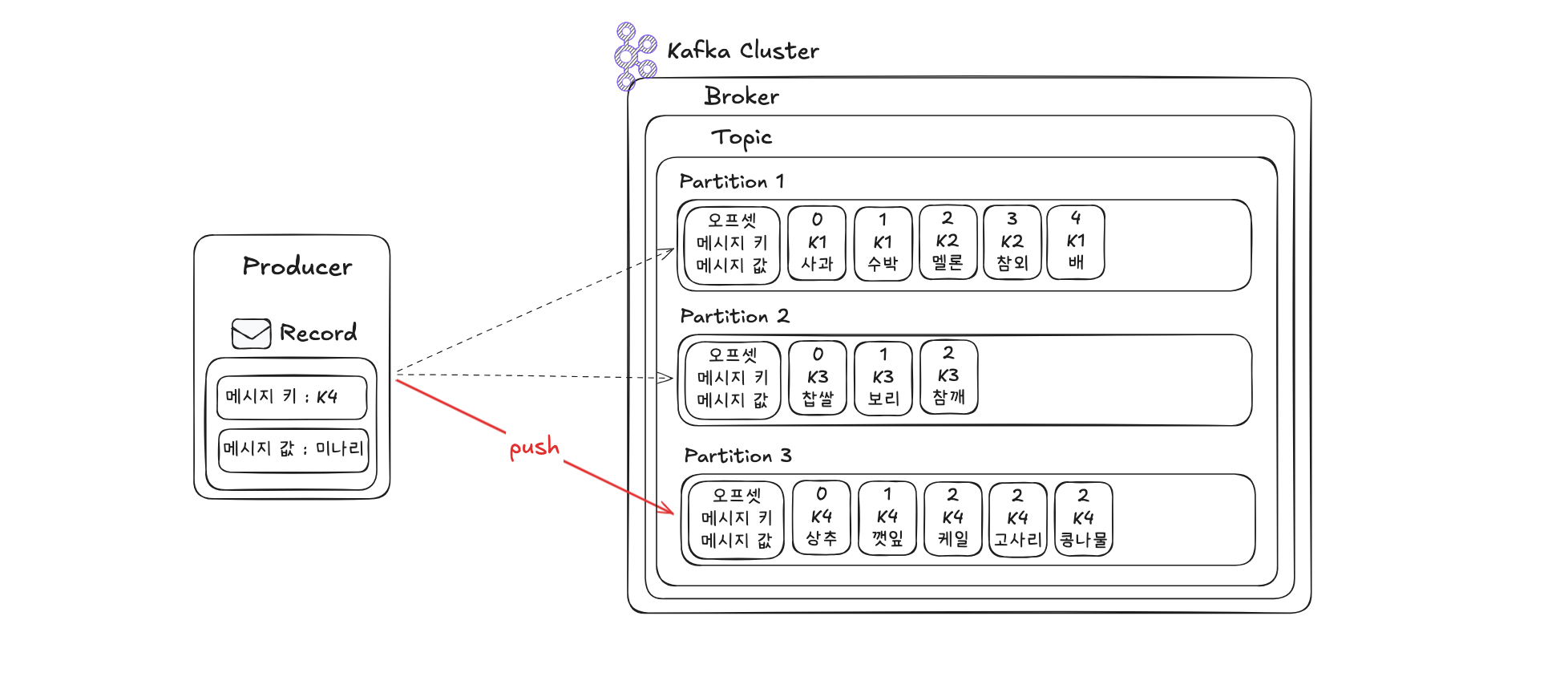
메시지 키를 지정하려면 ProducerRecord 생성 시 파라미터로 키를 추가하면 됩니다. 아래는 키를 포함한 메시지를 전송하는 예시입니다.
ProducerRecord<String, String> record = new ProducerRecord<>("topic", "key", "value");
또한, 파티션 번호를 명시적으로 지정하려면 다음과 같이 작성할 수 있습니다.
ProducerRecord<String, String> record = new ProducerRecord<>("topic", 2, "key", "value");이때 지정한 파티션 번호는 해당 토픽에 존재하는 번호여야 정상 동작합니다. 메시지 키가 포함된 메시지를 소비자 측에서 확인하려면, kafka-console-consumer 명령어에 --property print.key=true 및 --property key.separator=구분자 옵션을 함께 지정하시면 됩니다.
메시지 키를 가지지 않는 경우 사용되는 기본 파티셔너
- RoundRobinPartitioner (Kafka 2.5.0 이전 기본값)
메시지를 받은 순서대로 파티션에 순차적으로 분산합니다. 그러나 데이터가 여러 파티션에 나뉘다 보니, 배치 단위로 묶이기 어렵고, 이로 인해 처리 성능이 떨어질 수 있습니다. - UniformStickyPartitioner (Kafka 2.5.0 이후 기본값)
단일 파티션에 데이터를 집중시켜 배치 처리를 가능하게 하며, 높은 처리량과 낮은 리소스 사용률을 달성할 수 있습니다. 내부적으로는 하나의 파티션을 일정 시간 유지하면서 데이터를 배치로 전송하고, 이후에 다른 파티션으로 변경하는 방식으로 동작합니다.
두 파티셔너 모두 메시지 키가 있는 경우에는 메시지 키의 해시 값을 기준으로 파티션을 정한다는 점에서는 동일하지만, 메시지 키가 없는 경우에 UniformStickyPartitioner는 RoundRobin 방식의 단점을 개선하여 보다 균형 잡힌 파티션 분산과 높은 성능을 제공합니다.
사용자 정의 파티셔너
Kafka 클라이언트는 사용자 정의 파티셔너를 구현할 수 있도록 org.apache.kafka.clients.producer.Partitioner 인터페이스를 제공합니다. 이를 상속받아 사용자 정의 클래스를 작성하면 메시지 키나 메시지 값에 따라 원하는 파티션으로 데이터를 보낼 수 있습니다.
예를 들어, 메시지 키에 "관리자"라는 단어가 포함된 경우, 해당 메시지를 항상 특정 파티션으로 전송하도록 설정할 수 있습니다. 이 경우 토픽의 파티션 개수가 변경되더라도 해당 키는 특정 파티션으로 지속적으로 할당되도록 할 수 있습니다.
압축 옵션 설정
Kafka 프로듀서는 전송 시 데이터 압축을 설정할 수 있는 기능을 제공합니다. 기본적으로는 압축이 적용되지 않지만, gzip, snappy, lz4 등의 압축 알고리즘을 사용할 수 있습니다.
압축을 사용하면 네트워크 트래픽을 줄일 수 있지만, 압축 및 해제 시 CPU 리소스를 사용하게 되므로 시스템 상황에 따라 적절한 압축 방식을 선택해야 합니다. 또한, 프로듀서에서 압축된 메시지는 컨슈머 측에서 압축을 해제해야 하므로 컨슈머 측에서도 리소스 사용에 유의해야 합니다.
프로듀서 설정 옵션
| [필수 옵션] | |
| bootstrap.servers | Kafka 브로커의 호스트와 포트를 1개 이상 지정합니다. 일부 브로커 장애 시에도 안정적으로 연결할 수 있도록 최소 2개 이상 입력하는 것이 일반적입니다. |
| key.serializer | 메시지 키를 직렬화할 클래스. |
| value.serializer | 메시지 값을 직렬화할 클래스. |
| [선택 옵션] | |
| acks | 전송 성공 여부를 판단하는 기준입니다. 0: 전송 즉시 성공 처리 1: 리더 파티션에 저장되면 성공 (기본값) -1 또는 all: 리더 + 최소 복제본 저장 시 성공 |
| buffer.memory | 전송 전 데이터를 저장할 버퍼 메모리 크기. 기본값: 32MB |
| retries | 전송 실패 시 재시도 횟수. 기본값: Integer.MAX_VALUE (사실상 무제한) |
| batch.size | 배치 단위 전송 시 최대 메시지 크기. 기본값: 16KB |
| linger.ms | 배치 형성을 위해 기다리는 시간. 기본값: 0 (즉시 전송) |
| partitioner.class | 사용자 정의 파티셔너 클래스 설정. 기본값: DefaultPartitioner |
| enable.idempotence | 멱등성 프로듀서 여부 설정. 중복 방지를 위해 true 권장. 기본값: false |
| transaction.id | 트랜잭션 프로듀서로 동작하도록 설정. 고유 트랜잭션 ID를 지정해야 함 |
전송 결과 확인 방식
KafkaProducer의 send() 메서드는 Future<RecordMetadata> 객체를 반환하며, 이를 통해 동기적(sync)으로 전송 결과를 확인할 수 있습니다.
RecordMetadata metadata = producer.send(record).get();
System.out.println(metadata.topic());
System.out.println(metadata.partition());
System.out.println(metadata.offset());
동기 방식은 브로커의 응답을 기다려야 하므로 전송 속도에는 부담이 될 수 있습니다. 따라서, 빠른 전송이 필요한 경우에는 Callback 인터페이스를 활용하여 비동기적(async)으로 전송 결과를 확인하는 방법도 사용할 수 있습니다.
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.println("전송 성공: " + metadata.offset());
} else {
exception.printStackTrace();
}
});
그러나 전송 결과 확인이 중요한 경우에는 동기(sync) 방식을 선택하는 것이 더 안전합니다.
컨슈머(Consumer)
컨슈머는 프로듀서가 브로커에 전송한 데이터를 가져와 처리하는 역할을 담당합니다. 컨슈머는 브로커에 저장된 데이터를 효율적으로 소비하기 위해 다양한 방식으로 운영할 수 있으며, Kafka가 제공하는 구조와 옵션들을 적절히 활용하면 안정적이고 유연한 데이터 파이프라인을 구축할 수 있습니다.
컨슈머 운영 방식
컨슈머를 운영하는 방식은 크게 두 가지로 나눌 수 있습니다.
1. 컨슈머 그룹 기반 운영 방식
Kafka는 각기 다른 컨슈머 그룹을 통해 동일한 토픽에 대한 소비를 병렬로 수행할 수 있도록 지원합니다. 컨슈머 그룹 내에서는 각 컨슈머가 하나 이상의 파티션을 할당받아 데이터를 소비합니다. 이때, 하나의 파티션은 동시에 단 하나의 컨슈머에게만 할당될 수 있으며, 하나의 컨슈머는 여러 파티션을 소비할 수 있습니다.
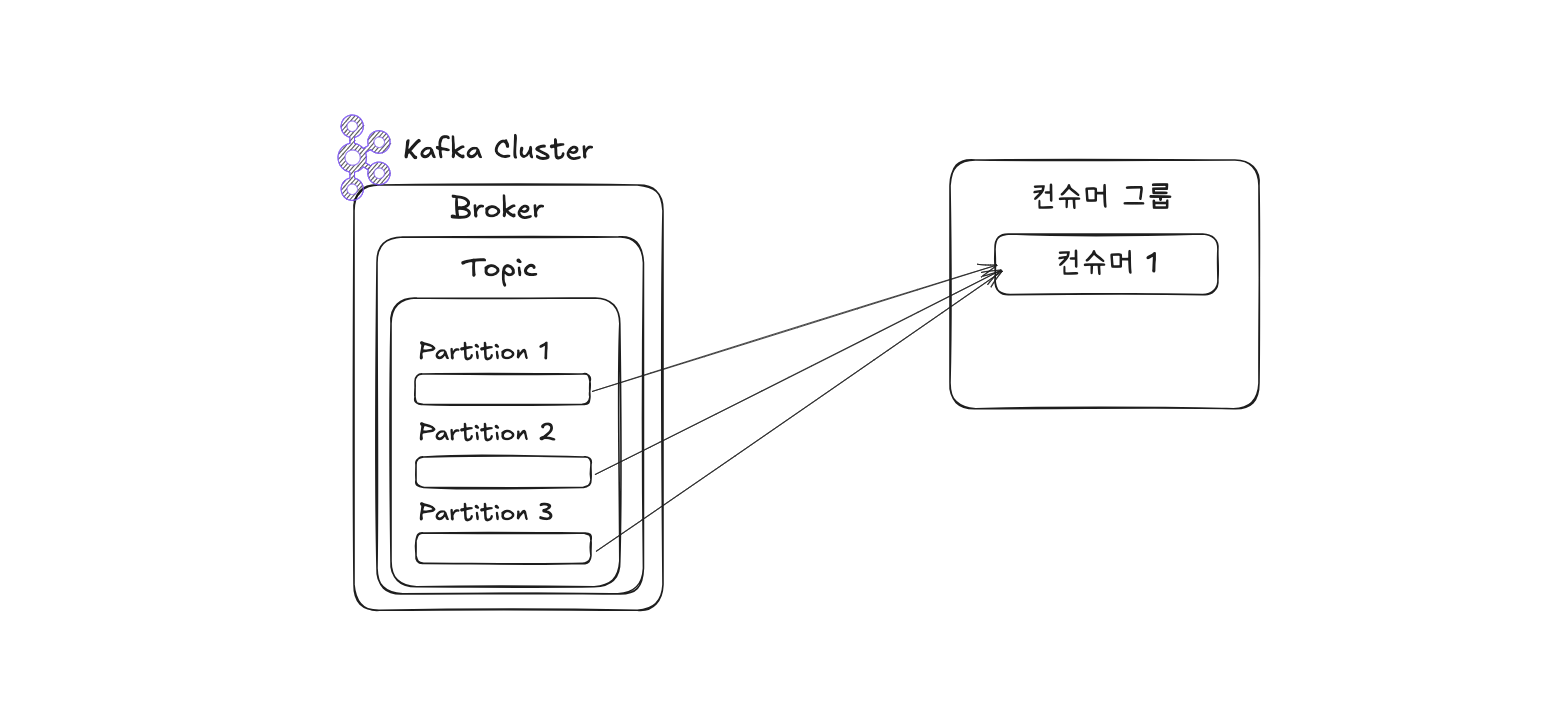
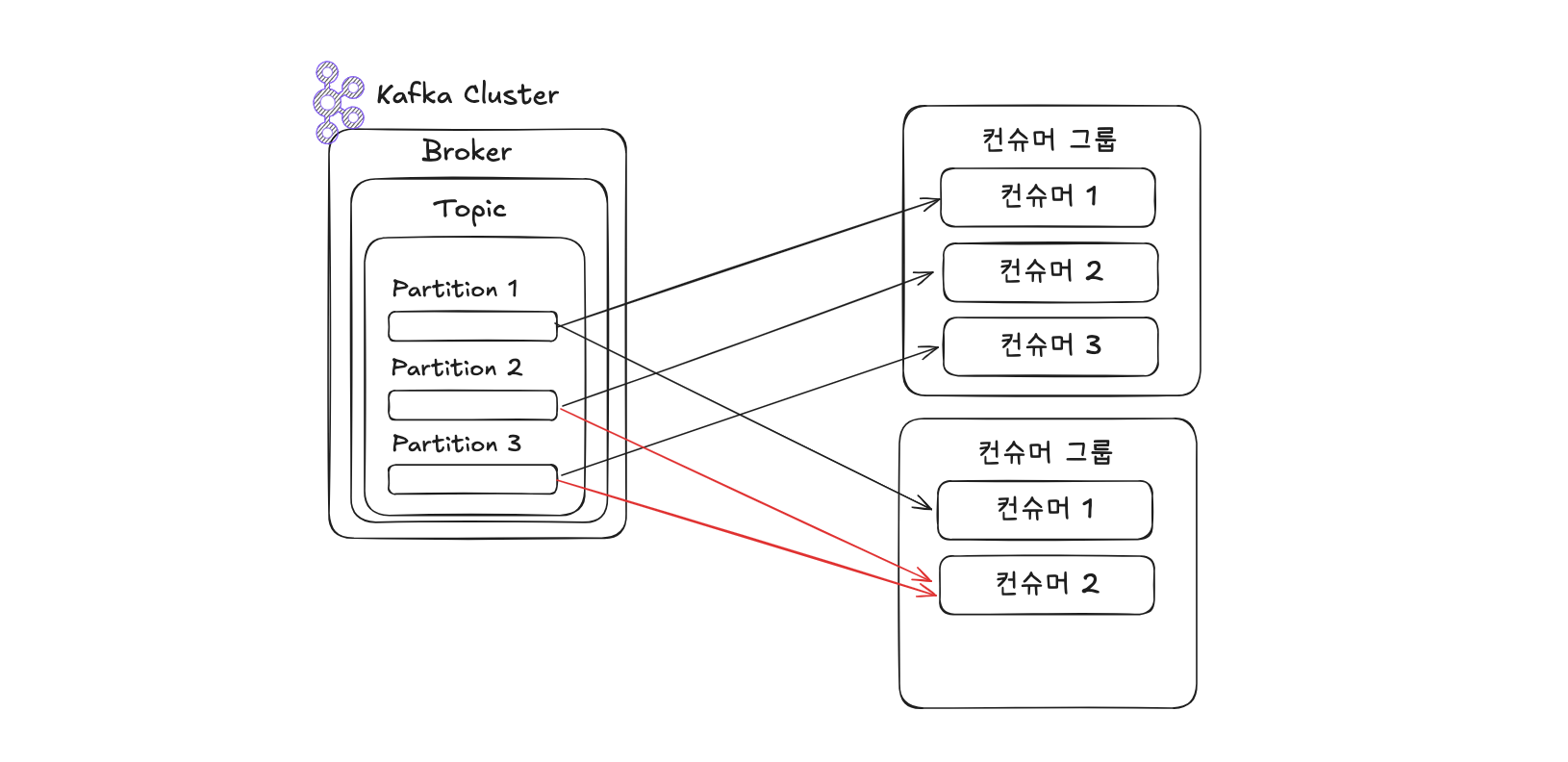
예를 들어 3개의 파티션을 가진 토픽을 처리하기 위해 3개 이하의 컨슈머로 구성된 컨슈머 그룹을 운영하는 것이 이상적입니다. 만약 4개의 컨슈머가 동일한 그룹에 속해 있다면, 1개의 컨슈머는 어떤 파티션도 할당받지 못해 유휴 상태로 남게 됩니다. 유휴 컨슈머는 불필요한 스레드를 차지하므로 애플리케이션 효율성을 저해할 수 있습니다.
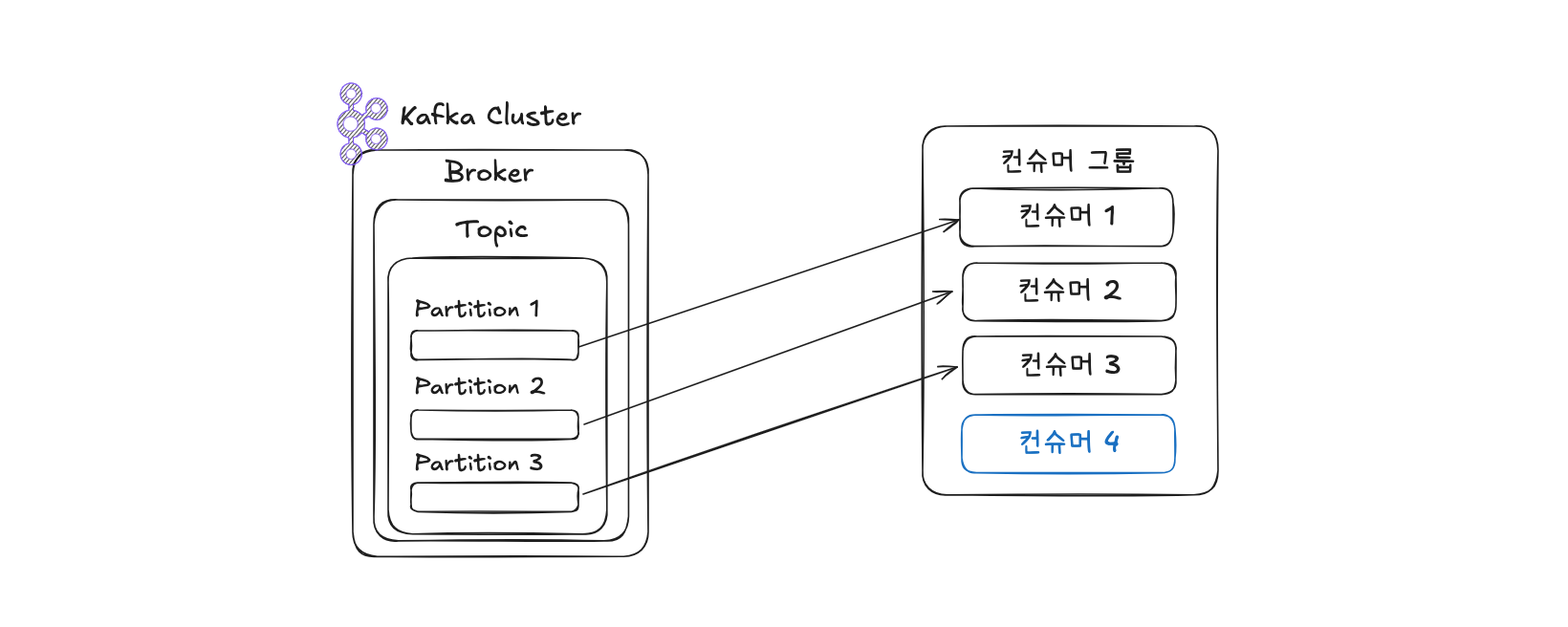
컨슈머 그룹은 서로 완전히 격리되어 운영되므로, 같은 토픽이라도 각각의 컨슈머 그룹은 독립적으로 데이터를 소비할 수 있습니다. 이를 활용하면 각기 다른 데이터 적재 목적에 따라 리소스 사용을 최적화할 수 있습니다. 예를 들어 CPU/메모리 리소스를 수집하는 데이터를 실시간으로 시각화하기 위해 Elasticsearch에 저장하고, 대용량 분석을 위해 Hadoop에도 동시에 적재하는 경우, 두 개의 컨슈머 그룹으로 나누어 운영하면 Elasticsearch 또는 Hadoop 중 하나에 장애가 발생해도 다른 한쪽의 데이터 적재에는 영향을 주지 않게 됩니다. 장애가 해결되면 해당 컨슈머 그룹은 마지막 커밋된 오프셋 이후부터 다시 데이터를 소비합니다.
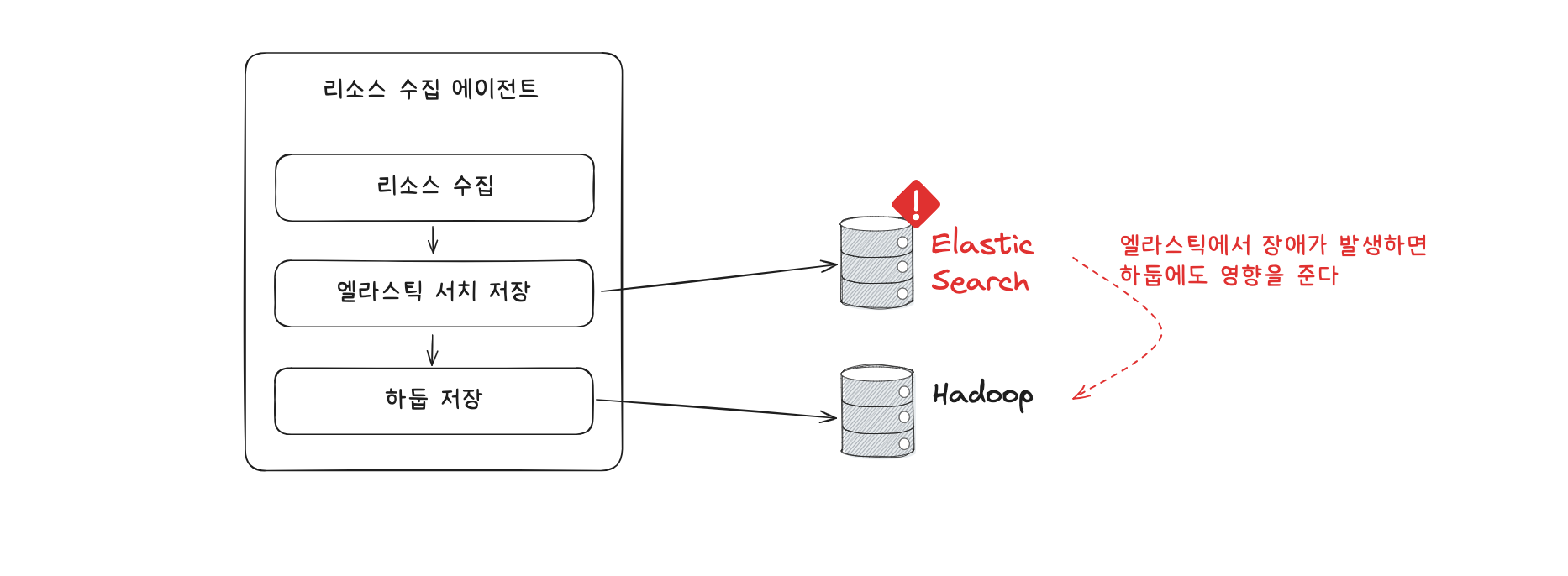


이처럼 컨슈머 그룹을 목적별로 분리하여 운영하는 것은 장애에 대한 격리성뿐 아니라 안정적인 데이터 흐름을 보장하는 데 매우 중요합니다. 반대로 하나의 컨슈머 그룹에서 두 저장소에 동시에 데이터를 적재하도록 구현하면, 특정 저장소의 장애가 전체 파이프라인의 병목을 유발할 수 있습니다.
2. 특정 파티션 직접 할당 방식
컨슈머는 subscribe() 메서드 외에도 assign() 메서드를 통해 특정 파티션을 명시적으로 할당받아 운영할 수 있습니다. 이 방식은 Kafka의 리밸런싱 메커니즘을 사용하지 않기 때문에 컨슈머가 담당할 파티션을 직접 제어할 수 있으며, 파티션 변경이 없는 고정 처리 구조에 적합합니다. 할당된 파티션은 assignment() 메서드를 통해 조회할 수 있습니다.
리밸런싱(Rebalancing)과 장애 대응
컨슈머 그룹 내에서 컨슈머가 추가되거나 제거될 경우 Kafka는 자동으로 파티션을 재분배하며, 이 과정을 리밸런싱이라 부릅니다. 리밸런싱이 발생하면 일부 컨슈머는 잠시 데이터를 소비하지 못하게 되므로, 이 과정이 자주 발생하면 성능 저하로 이어질 수 있습니다.
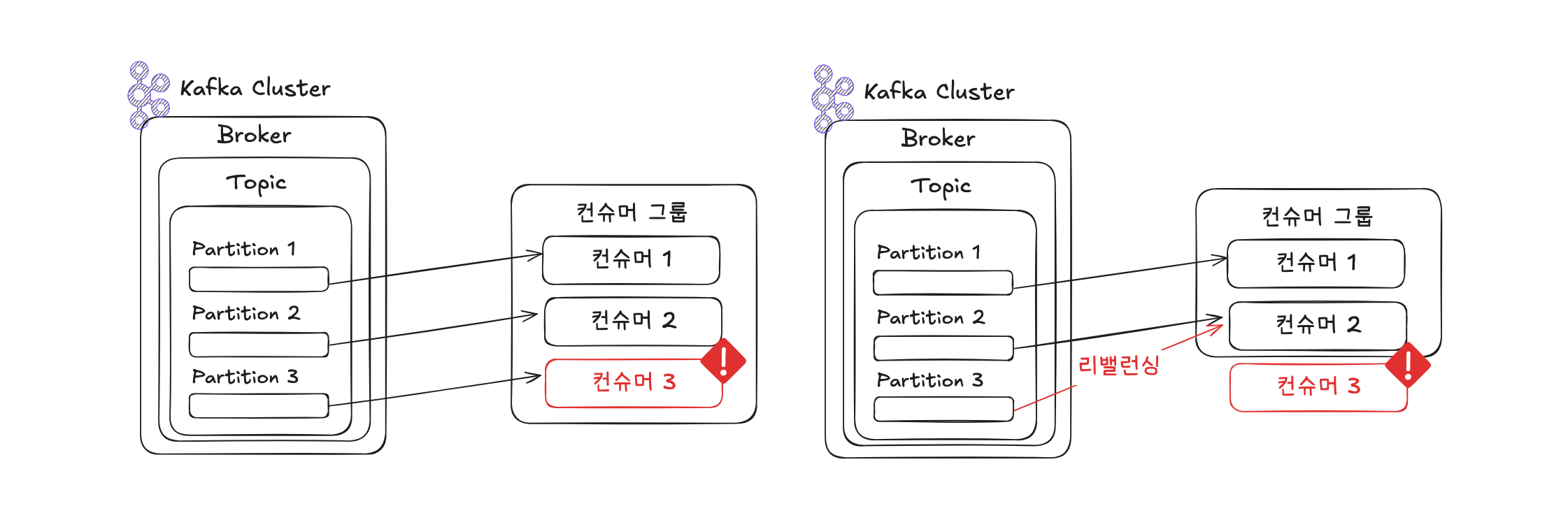
Kafka에서는 그룹 조정자(Group Coordinator)가 리밸런싱을 감지하고 수행합니다. 이 역할은 Kafka 브로커 중 한 대가 맡게 됩니다. 리밸런싱 시 오프셋 손실 또는 중복 처리를 방지하기 위해 Kafka는 ConsumerRebalanceListener 인터페이스를 제공합니다.
onPartitionRevoked() 메서드를 활용하면 파티션 반환 직전에 커밋을 수행하여, 다음 할당자(컨슈머)가 이어서 데이터를 소비할 수 있도록 할 수 있습니다. 그러나 이 커밋이 이루어지기 전에 애플리케이션에 장애가 발생하면 해당 커밋은 Kafka 브로커에 저장되지 않으며, 이로 인해 일부 데이터가 중복 처리될 수 있습니다.
오프셋 커밋 전략
Kafka는 컨슈머가 데이터를 어디까지 처리했는지 확인하기 위해 오프셋을 관리합니다. 오프셋 정보는 Kafka 내부 토픽인 __consumer_offsets에 저장되며, 다음 소비 시점을 결정하는 기준이 됩니다.

1. 자동 커밋 (비명시적 커밋)
- 설정: enable.auto.commit=true
- 주기: auto.commit.interval.ms (기본값: 5000ms)
- 특징: poll() 호출 주기와 커밋 간격에 따라 오프셋 자동 저장
- 단점: poll 이후 장애 발생 시, 처리된 데이터에 대한 커밋이 이루어지지 않아 중복 가능성 존재
2. 동기 커밋 (commitSync)
- poll() 이후 명시적으로 commitSync()를 호출하여 커밋 수행
- 안정적인 오프셋 저장이 가능하지만 커밋 응답을 기다리는 동안 처리 지연 발생
- 커밋 요청은 poll()으로 받은 레코드 중 마지막 오프셋 기준으로 수행됨
- 개별 커밋을 원하는 경우 commitSync(Map<TopicPartition, OffsetAndMetadata>) 형식 사용 가능
3. 비동기 커밋 (commitAsync)
- 커밋 요청을 전송한 후 응답을 기다리지 않고 바로 다음 처리를 수행
- 처리량은 높지만, 실패 시 순서 보장 어려움
- 커밋 결과는 OffsetCommitCallback 인터페이스를 통해 비동기로 확인 가능
- onComplete() 메서드를 통해 성공 여부 및 커밋된 오프셋 확인 가능
컨슈머 내부 구조
Kafka 컨슈머는 poll() 메서드를 호출하는 시점에 클러스터로부터 데이터를 가져오는 것이 아니라, 내부의 fetcher 스레드가 백그라운드에서 데이터를 미리 받아와 큐에 저장해 놓습니다. poll()을 호출하면 해당 큐에서 데이터를 반환하게 됩니다. 이 구조 덕분에 poll() 응답 속도를 높일 수 있습니다.
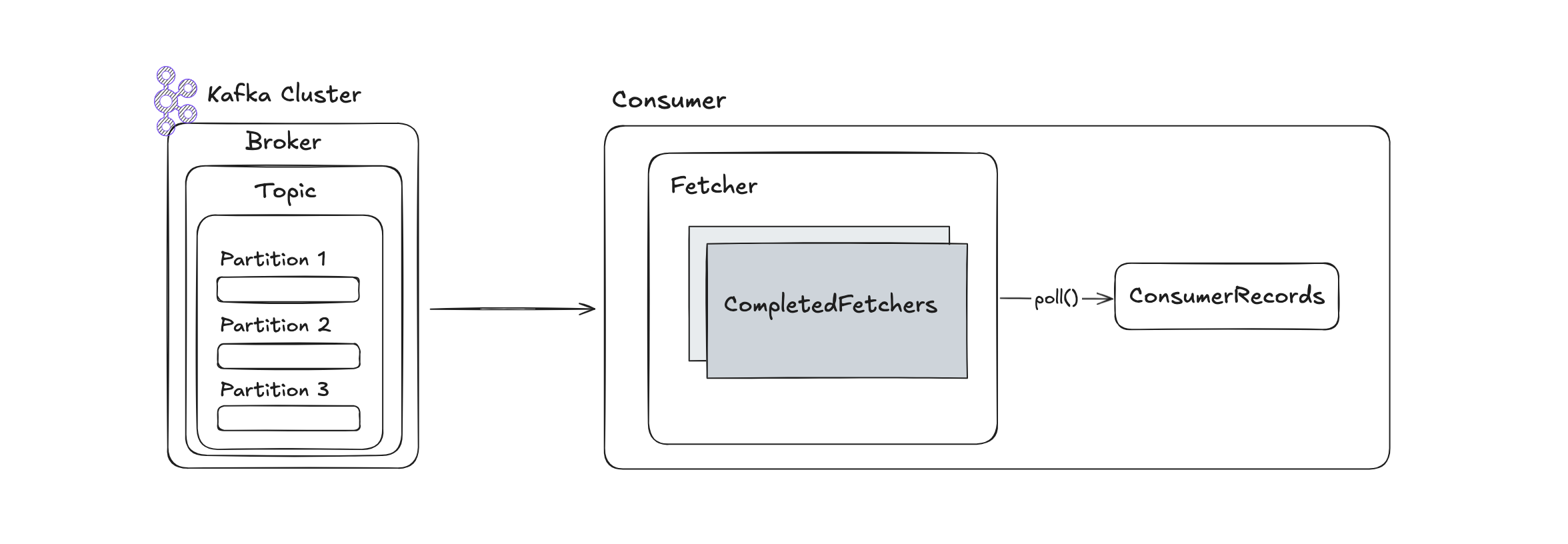
안전한 컨슈머 종료 방식
Kafka 컨슈머는 안전하게 종료되어야 하며, 그렇지 않을 경우 컨슈머 그룹에서 해당 컨슈머가 제거되지 않아 세션 타임아웃이 발생할 때까지 리소스를 차지하게 됩니다. 이로 인해 파티션 데이터가 소비되지 않고 컨슈머 랙이 증가하게 되며, 이는 처리 지연으로 이어질 수 있습니다.
Kafka는 안전한 종료를 위해 wakeUp() 메서드를 제공합니다. 해당 메서드는 블로킹 상태의 poll() 호출을 중단시키고 WakeupException을 발생시킵니다. 이 예외를 처리한 후 리소스를 해제하고, 마지막에 close() 메서드를 호출하여 Kafka 클러스터에 컨슈머 종료를 알리는 방식으로 안전한 종료가 이루어집니다.
Java에서는 Runtime.getRuntime().addShutdownHook()을 활용하여 종료 시점에 지정된 스레드를 실행할 수 있으며, 이를 통해 wakeUp() → 리소스 해제 → close() 순으로 처리하면 안전한 셧다운이 가능합니다.
주요 설정 옵션
| [필수 옵션] | |
| bootstrap.servers | Kafka 브로커 주소 목록 |
| key.deserializer | 메시지 키 역직렬화 클래스 |
| value.deserializer | 메시지 값 역직렬화 클래스 |
| [선택 옵션] | |
| group.id | 컨슈머 그룹 ID (subscribe() 사용 시 필수) |
| auto.offset.reset | 저장된 오프셋이 없을 경우 어디서부터 읽을지 설정 (latest, earliest, none) |
| enable.auto.commit | 자동 커밋 여부 설정 (기본값: true) |
| auto.commit.interval.ms | 자동 커밋 간격 (기본값: 5000ms) |
| max.poll.records | poll() 호출 시 반환할 최대 레코드 수 (기본값: 500) |
| session.timeout.ms | 브로커와의 연결 타임아웃 (기본값: 10000ms) |
| heartbeat.interval.ms | 하트비트 전송 간격 (기본값: 3000ms) |
| max.poll.interval.ms | poll() 호출 간 최대 시간 (기본값: 300000ms) |
| isolation.level | 트랜잭션 메시지 처리 수준 (read_committed, read_uncommitted) |
어드민
운영 환경에서는 단순히 데이터를 주고받는 것뿐 아니라, Kafka 클러스터의 설정을 확인하고 동적으로 관리하는 작업도 매우 중요합니다. 보통 브로커에 직접 접속하여 설정을 확인할 수 있지만, 이는 번거롭고 자동화하기 어렵습니다. Kafka는 이러한 설정을 손쉽게 제어할 수 있도록 AdminClient 클래스를 제공합니다. 이를 통해 운영 자동화 및 상태 점검을 프로그램 수준에서 수행할 수 있습니다.
AdminClient를 사용하면 다음과 같은 작업을 수행할 수 있습니다.
- 클러스터 상태 정보 조회 (브로커 목록, 컨트롤러 ID 등)
- 전체 토픽 목록 조회 및 세부 설정 확인
- 신규 토픽 생성 및 파티션 개수 변경
- 컨슈머 그룹 목록 및 오프셋 정보 조회
- 토픽 삭제 요청 수행
- ACL(접근 제어 규칙) 생성 및 조회
운영 자동화 도구 또는 관리 대시보드를 구축할 때 AdminClient는 매우 유용하게 활용될 수 있으며, Kafka 클러스터에 대한 실시간 점검과 제어를 가능하게 해줍니다.
'Kafka, RabbitMQ' 카테고리의 다른 글
| 카프카(kafka)에 대해 알아보자 - (5) 카프카 딥다이브 (프로듀서, 컨슈머) (2) | 2025.05.28 |
|---|---|
| 카프카(kafka)에 대해 알아보자 - (4) 카프카 딥다이브 (토픽, 파티션) (0) | 2025.05.27 |
| 카프카(kafka)에 대해 알아보자 - (1) 카프카의 기본 개념 (브로커, 토픽, 파티션, 레코드) (0) | 2025.05.23 |
| 카프카(kafka)에 대해 알아보자 (0) | 2025.05.23 |
| RabbitMQ에 대해 알아보자 - (12) Producer 트랜잭션 전략 (0) | 2025.05.20 |



